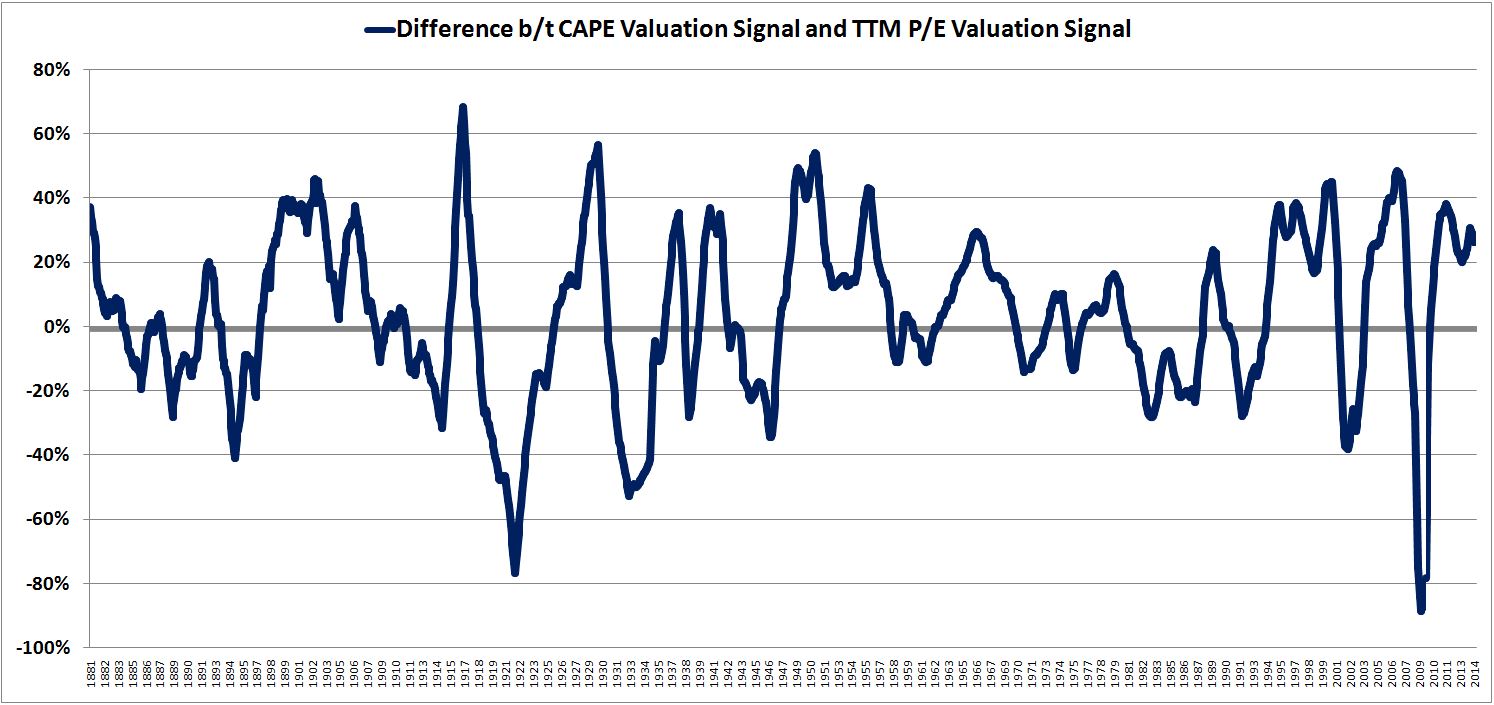
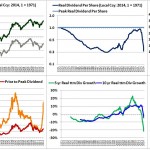
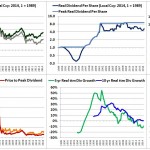
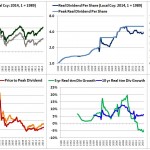
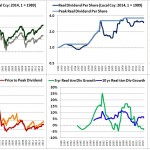
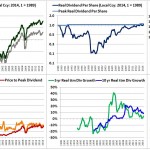
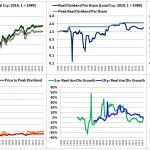
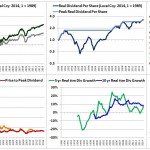
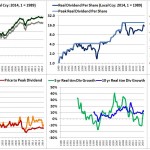
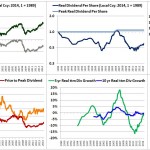
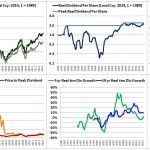
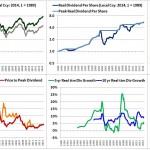
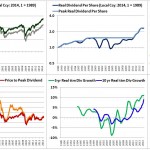
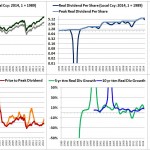
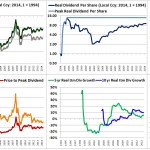
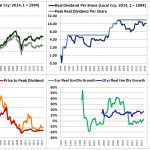
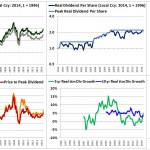
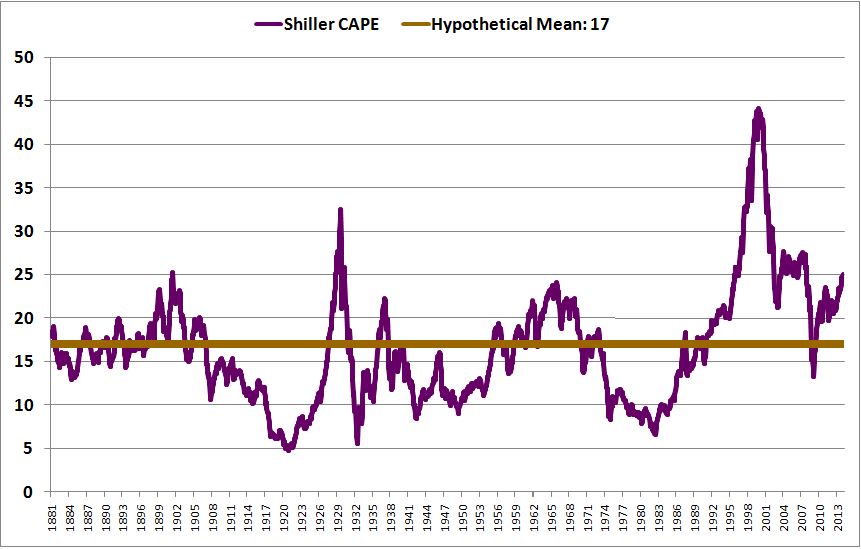
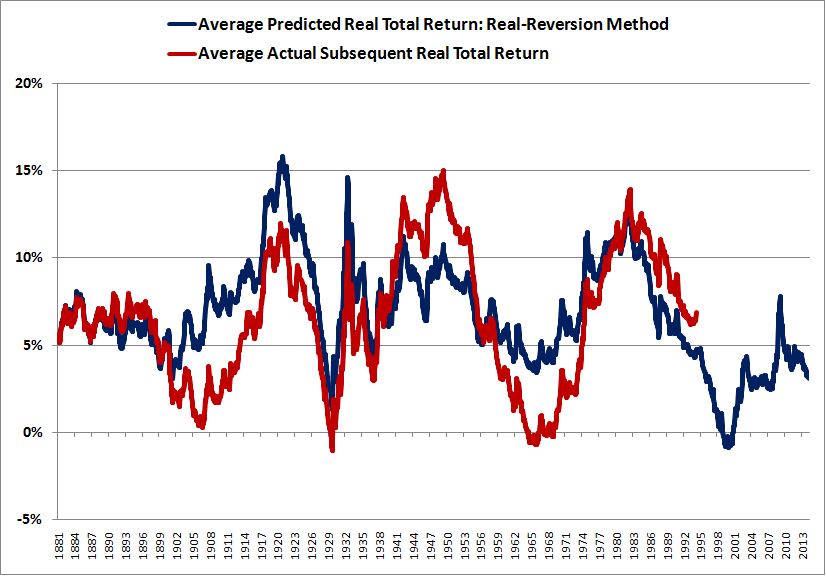
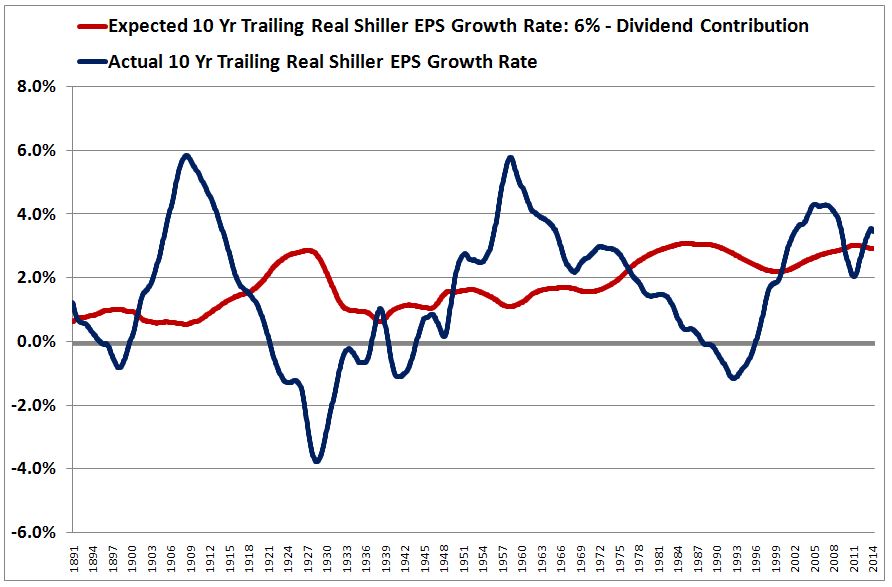
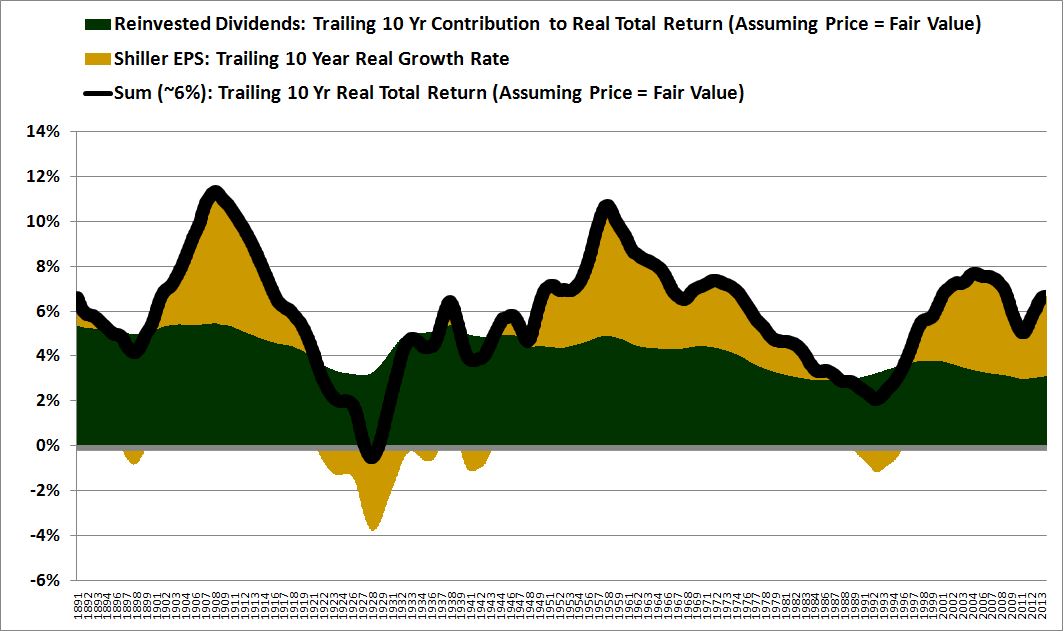
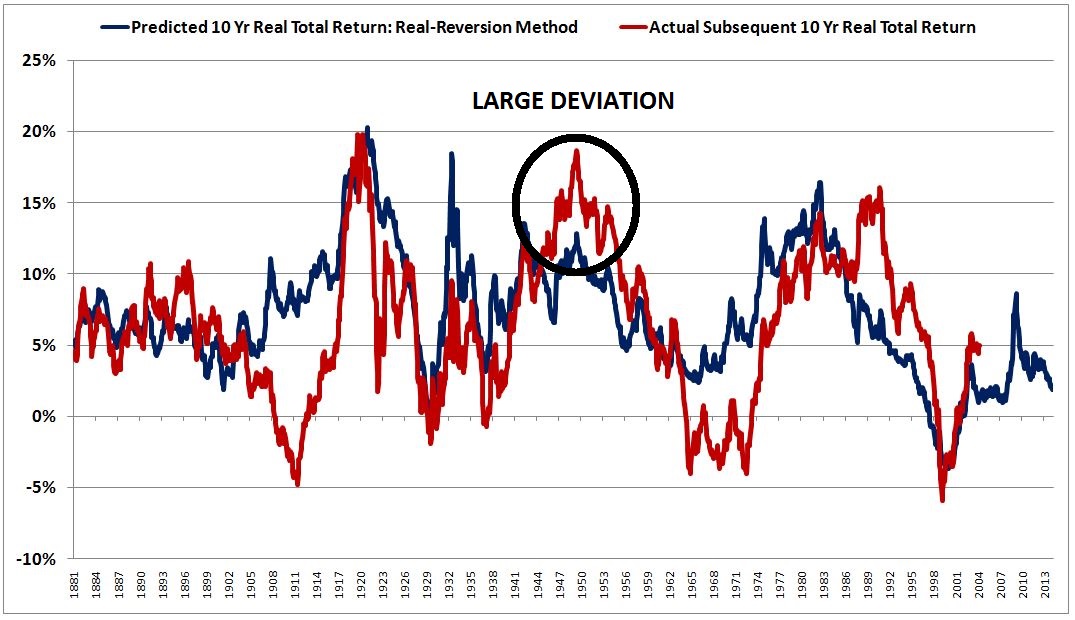
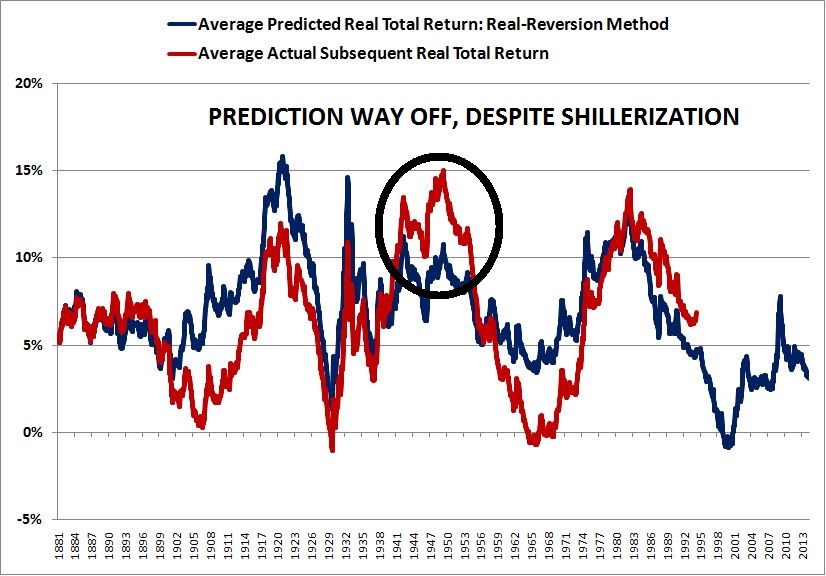
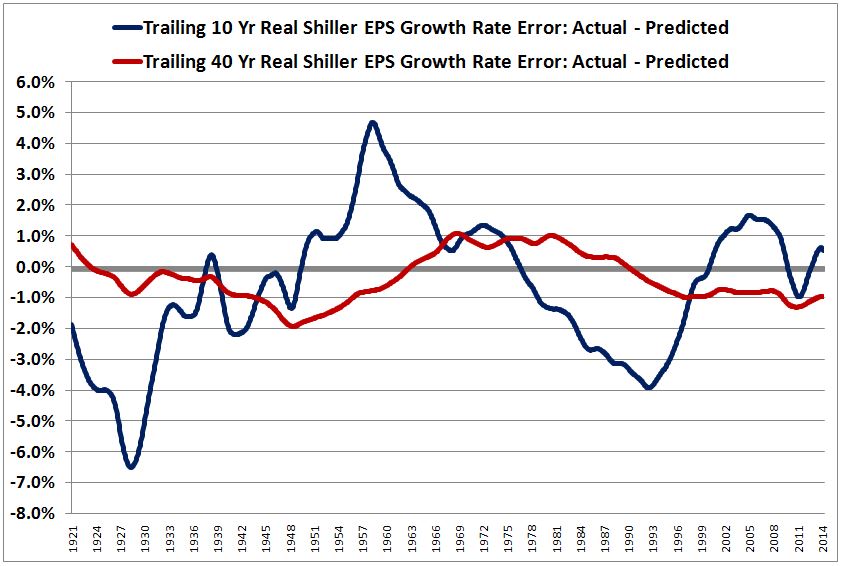
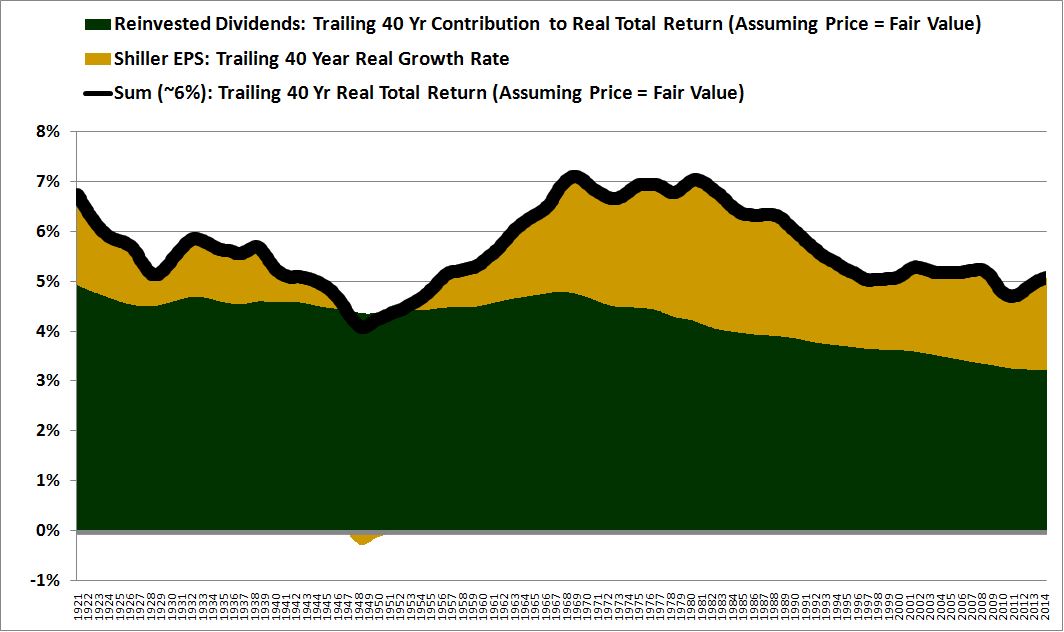
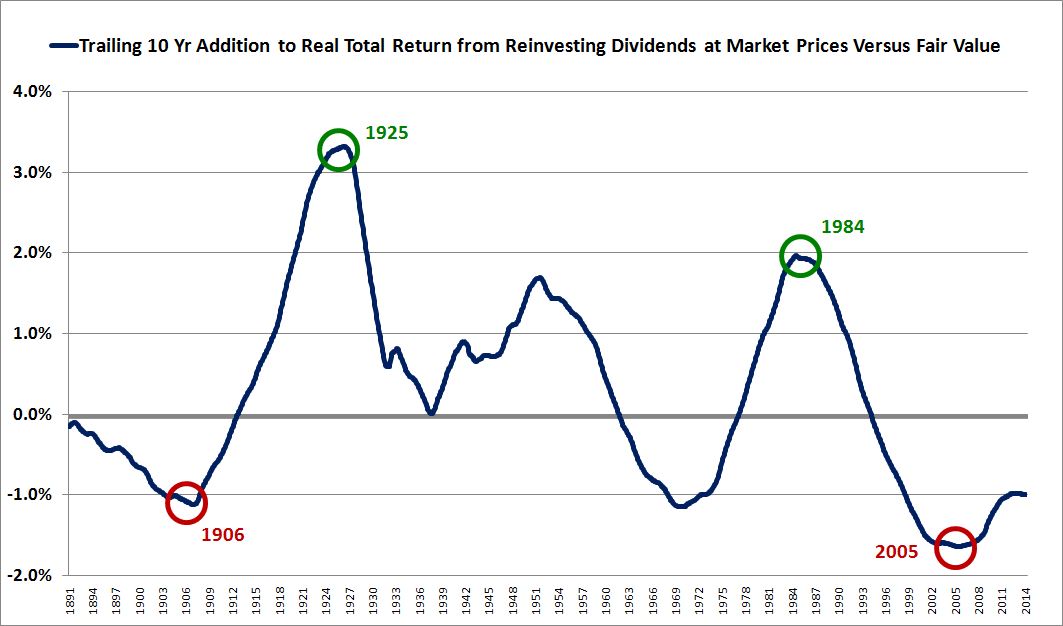
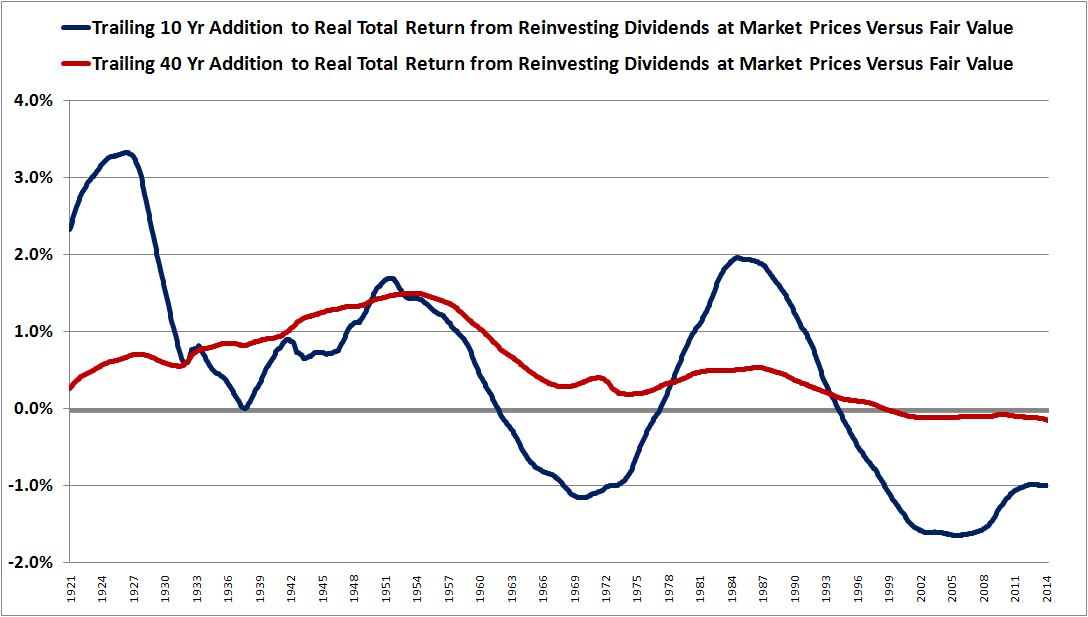
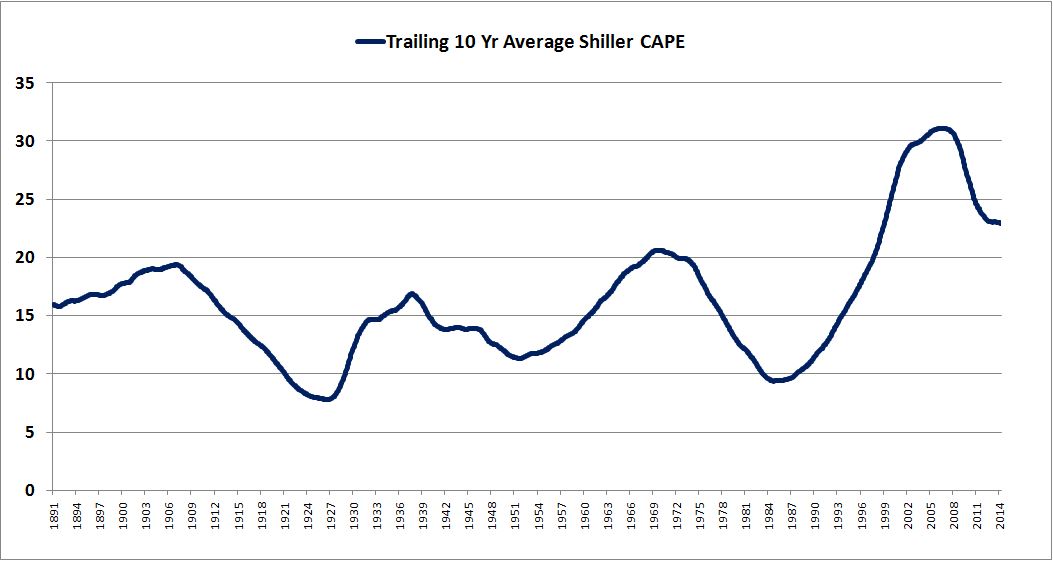
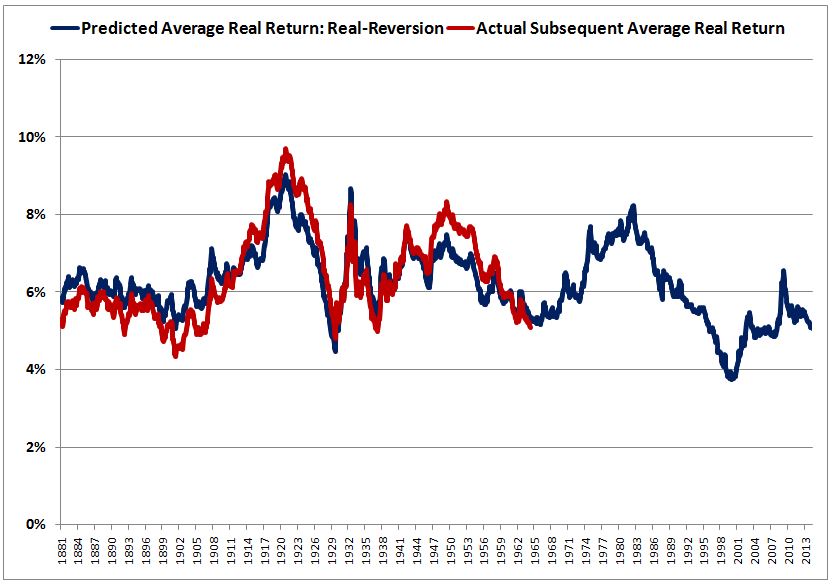
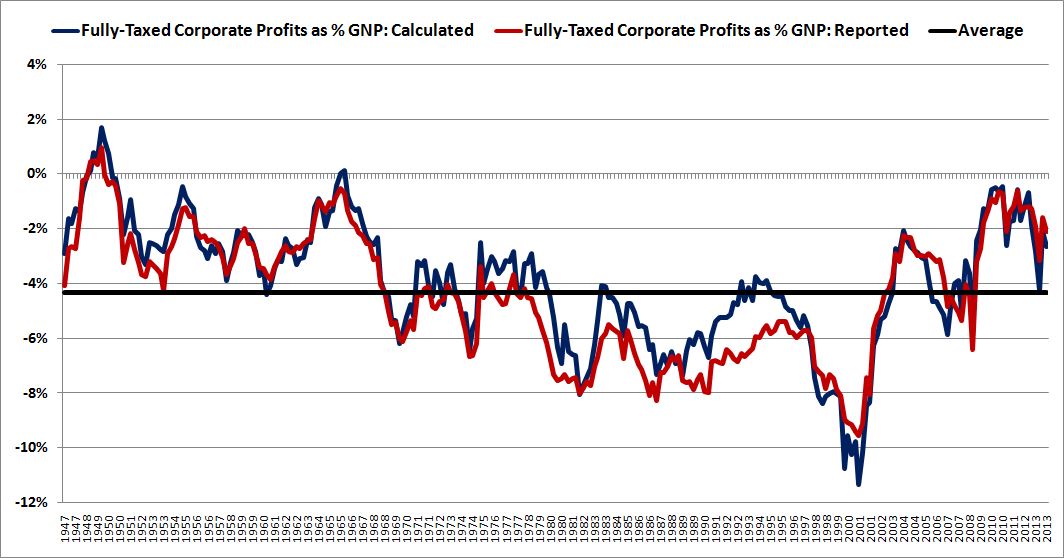
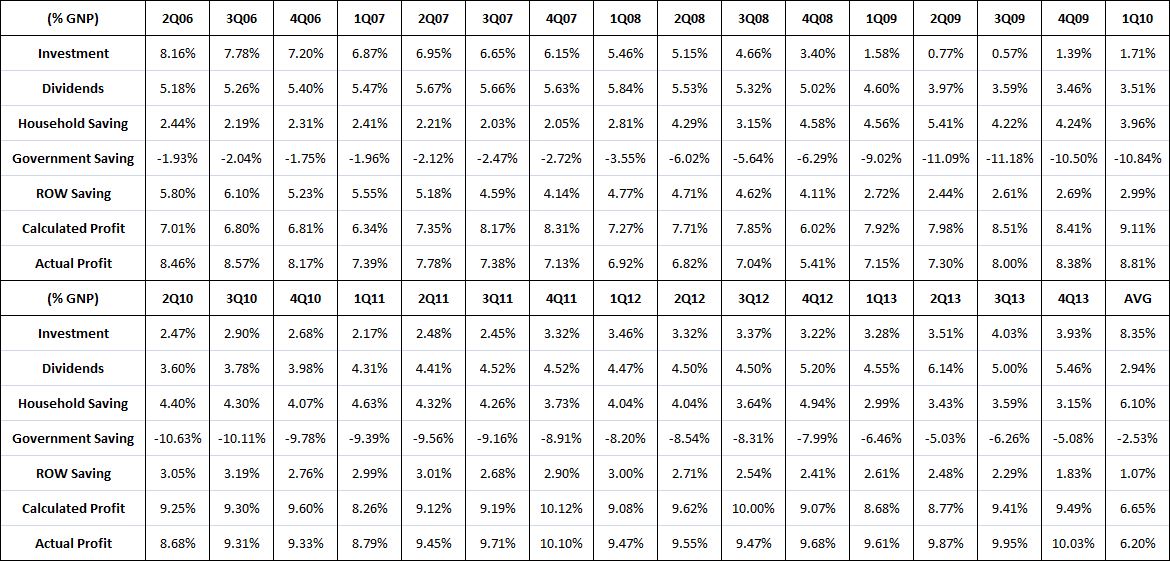
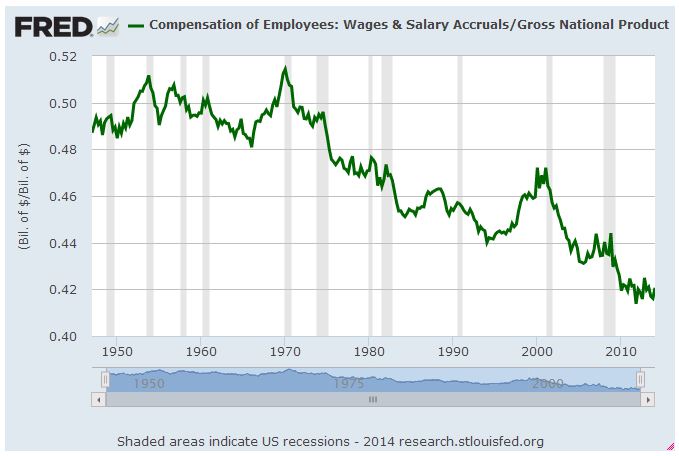
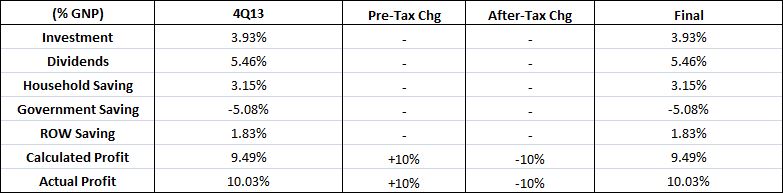
Over the last ten years, the “collectibles” market has produced a fantastic return for investors. According to the Knight Frank Luxury Investment Index, classic cars are up 550%, coins and stamps are up 350%, and fine wine and art are up 300%, with coveted items inside these spaces up by even greater amounts.
Over the last ten years, the “collectibles” market has produced a fantastic return for investors. According to the Knight Frank Luxury Investment Index, classic cars are up 550%, coins and stamps are up 350%, and fine wine and art are up 300%, with coveted items inside these spaces up by even greater amounts.
Why have collectibles performed so well, so much better than income earning assets like stocks and bonds? Here’s a simple answer. Over the last ten years, the supply of collectibles–especially those that are special in some way–has stayed constant. In the same period, the demand for collectibles–driven by the quantity of idle financial superwealth available to chase after them–has exploded. When supply stays constant, and demand explodes, price goes up–sometimes, by crazy amounts.
For collectibles, “supply” is a crucial factor in determining price. Often, the reason that a collectible becomes a collectible is that an anomaly makes it unusually rare, as was the case with the T206 Honus Wagner baseball card, shown above. The card was designed and issued by the American Tobacco Company–one of the original 12 members of the Dow–as part of the T206 series for the 1909 season. But Wagner refused to allow production of the card to proceed. Some say that he refused because he was a non-smoker and did not want to participate in advertising the bad habit of smoking to children. Others say that he was simply greedy, and wanted to receive more money for the use of his image. Regardless, fewer than 200 issues of the card were manufactured, with even fewer released to the public, in comparison with hundreds of thousands of issuances of other cards in the series. This anomaly turned an otherwise unremarkable card into a precious collectible that has continued to appreciate in value to this day. The card most recently traded for $2,800,000, more than 100 times its price 30 years ago, even as baseball and baseball card collecting have waned in popularity.
A Similar Effect in Financial Assets?
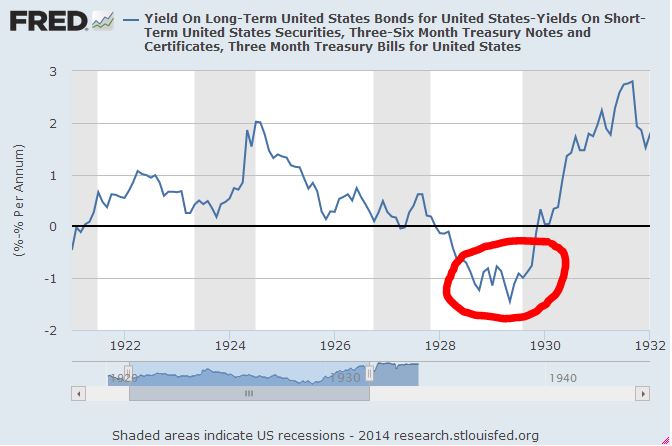
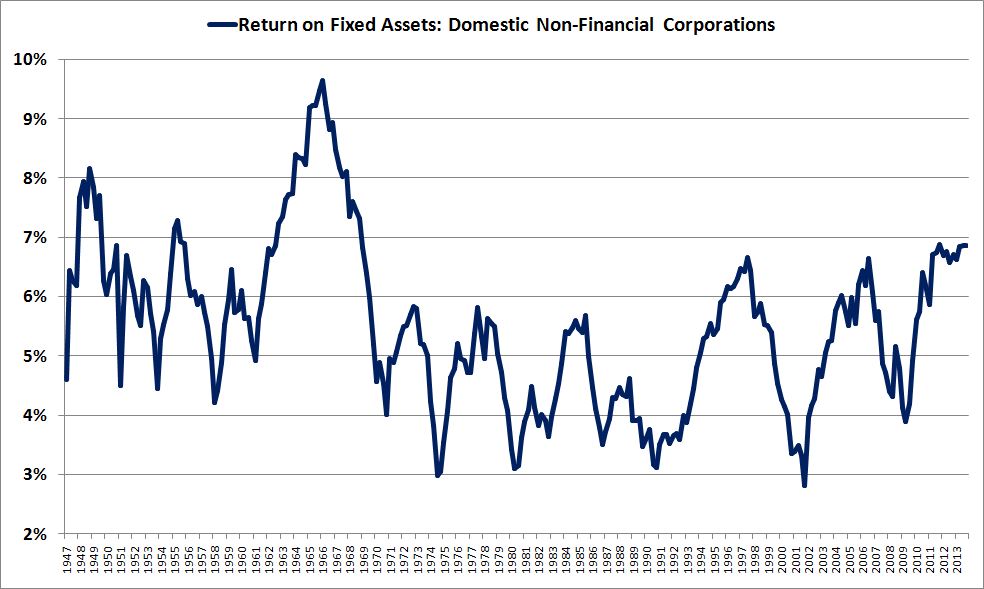
Since 2009, the Federal Reserve and foreign central banks have purchased an enormous quantity of long-term U.S. Treasury bonds. At the same time, the quantity of idle liquidity in the financial system available to chase after these bonds has greatly increased, with central banks issuing new cash for each bond they purchase, and also offering to loan new cash to banks at near zero interest on request. Might this fact help explain why U.S. Treasuries–and bonds in general–have become so expensive, with yields so unexplainably low relative to the strengthening U.S. growth and inflation outlook? (h/t Anti Petajisto)
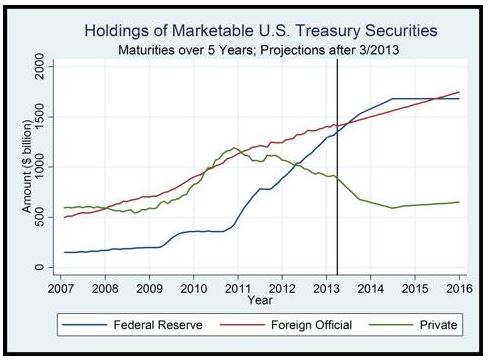
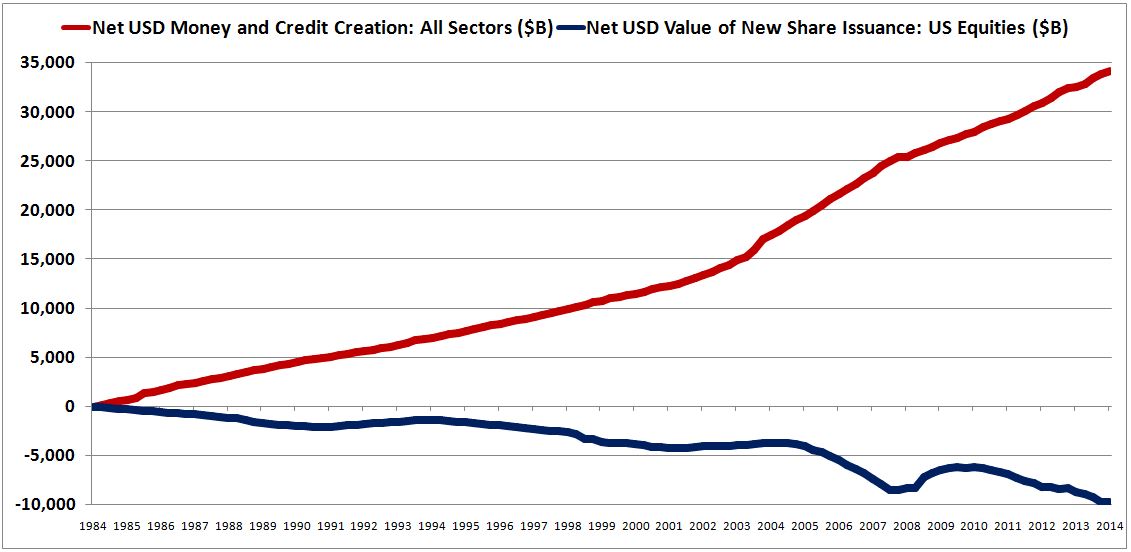
Similarly, over the last 30 years, the U.S. corporate sector has been aggressively reducing its outstanding shares, taking them off the market through buybacks and acquisitions. A continually growing supply of money and credit has thus been left to chase after a continually narrowing supply of equity. Might this fact help explain why stocks have become so expensive relative to the past, so relentlessly inclined to grind higher, no matter the news?
In this piece, I’m not going to try to answer these questions. Rather, I’m going to present a framework for answering them. The purpose of the framework will be to help the reader answer them, or at least think about them more clearly.
Supply and Demand: Introducing A Simple Housing Model
We often think about the pricing of financial assets in terms of theoretical constructs–“fair value”, “risk premium”, “discounted cash flow”, “net present value”, and so on. But the actual pricing of assets in financial markets is driven by forces that are much more basic: the forces of supply and demand. At a given market price, what amount of an asset–how many shares or units–will people try to buy? What amount of the asset–how many shares or units–will people try to sell? If we know the answer to these questions, then we know everything there is to know about where the price is headed.
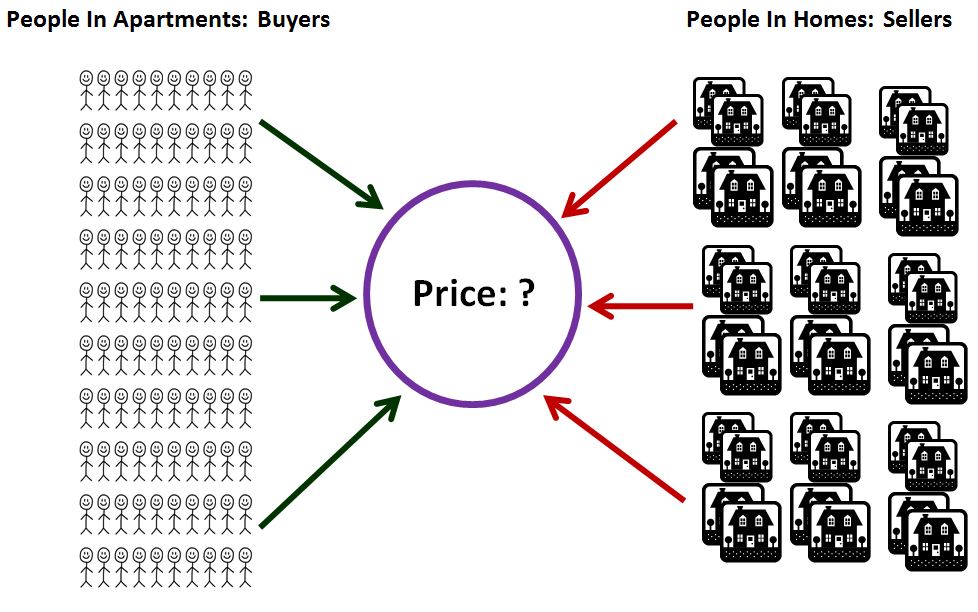
To sharpen this insight, let’s consider a simple, closed housing market consisting of some enormously large number of individuals–say, 10 billion, enough to make the market reliably liquid. Each individual in this market can either live in a home, or in an apartment. The rules for living in homes and apartments are as follows:
(1) To live in a home, you must own it.
(2) If you own a home, you must live in it.
(3) Only one person can live in a home at a time.
(4) A person can only own one home at a time.
(5) New homes cannot be built, because there is no new land to support building.
(6) Whoever does not live in a home must live in an apartment.
(Note: We introduce these constraints into the model not because they are realistic, but because they make it easier to extend the model to financial assets, which we will do later.)
Now, let’s suppose that the homes are perfectly identical to each other in all respects. Furthermore, let’s suppose that each of the homes has already been purchased, and already has an individual living inside it. Finally, let’s suppose that there is a sufficient supply of apartment space available for the total number of people that are not in homes to live in, and that the rent is stable and cheap. But the apartments aren’t very nice. The homes, in contrast, are quite nice–beautiful, spacious, comfortable. Unfortunately, there are only 1 billion homes in existence, enough for 10% of the individuals in the economy to live in. The other 9 billion individuals in the economy, 90%, will have to accept living in apartments, whether they want to or not.
At any given moment, some number of people in homes that want to collect cash and downgrade into apartments are going to try to sell. Conversely, some number of people in apartments that want to spend the money to upgrade are going to try to buy. The way the market executes transactions between those that want to buy and those want to sell is as follows. At the beginning of every second, a computer, remotely accessible to all members of the economy, displays a price. Those that want to buy homes at the displayed price send buy orders into the computer. Those that want to sell homes at the displayed price send sell orders into the computer. Note that these orders is are orders to transact at the displayed price. It’s not possible to submit orders to transact at other prices. At the end of the second, the computer takes the buy orders and sell orders and randomly matches them together, organizing transactions between the parties.
Now, here’s how the price changes. If the number of buy orders submitted in a given second equals the number of sell orders, or if there are no orders, then the price that the computer will display for transaction in the next second will be the same as in the previous second. If the number of buy orders submitted in a given second is greater than the number of sell orders, such that not all buy orders get executed, then the computer will increase the price displayed for transaction in the next second by some calculated amount, an amount that will depend on how many more buy orders there were than sell orders. If the number of buy orders submitted in a given second is less than the number of sell orders, then the same process happens in the opposite direction.
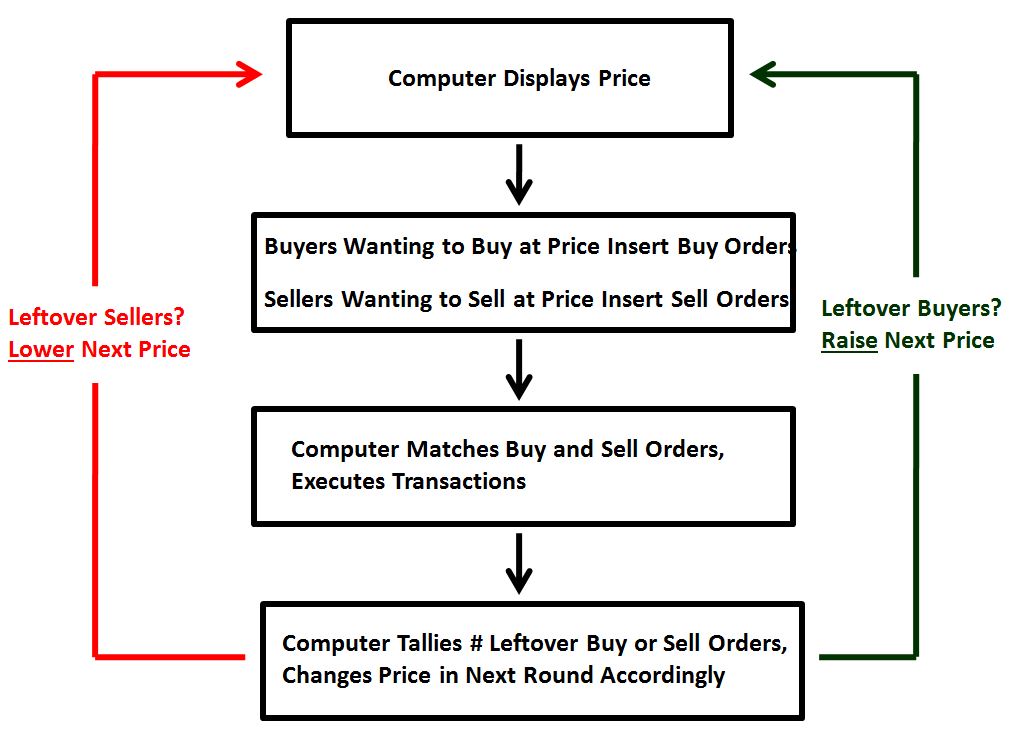
The purpose of this model is to provide a useful approximation of the price dynamics of actual markets. The key difference between the model and a real market is that the model constrains buyers and sellers such that they can only offer to buy or sell at the displayed price, with the displayed price changing externally based on whether an excess of buyers or sellers emerges. The reason we insert this constraint is to make the market’s path to equilibrium easy to conceptually follow–the path to equilibrium proceeds in a step by step manner, with the market trying out each price, and moving higher or lower based on which flow is greater at that price: buying flow or selling flow. But the constraint doesn’t change the eventual outcome. The price dynamics and the final equilibrium price end up being similar to what they would be in a real market where investors can accelerate the market’s path to equilibrium by freely shifting bids and asks.
Unpacking the Model: The Price Equation
The question we want to ask is, at what price–or general price range–will our housing market eventually settle at? And if prices are never going to settle in a range, if they are going to continually change by significant, unpredictable amounts, what factors will set the direction and magnitude of the specific changes?
To answer this question, we begin by observing that the displayed price will change until a condition emerges in which the average number of buy orders inserted per unit time at the displayed price equals–or roughly equals–the average number of sell orders inserted per unit time at the displayed price. Can you see why? By the rules of the computer, if they are not equal, the price will change, with the magnitude of the change determine by the degree of unequalness. So,
(1) Buy_Orders(Price) = Sell_Orders(Price)
“Price” is in parentheses here to indicate that the average number of buy orders that arrive in the market per unit time and the average number of sell orders that arrive in the market per unit time are functions of the price. When the price changes, the average number of buy orders and sell orders changes, reflecting the fact that buyers and sellers are sensitive to the price they pay. They care about it–a lot.
Now, we can separate Buy_Orders(Price), the average number of buy orders that occurs at a given price in a given period of time, into a supply term and a probability term.
Let Supply_Buyers be the supply term. This term represents the number of potential buyers, which equals the number of individuals living in apartments–per our assumptions, 9 billion.
Let Probability_Buy(Price) be the probability term. This term represents the average probability or likelihood that a generic potential buyer–any unspecified individual living in an apartment–will submit a buy order into the market in a given unit of time at the given price.
Combining the supply and probability terms, we get,
(2) Buy_Orders(Price) = Supply_Buyers * Probability_Buy(Price)
What (2) is saying is that the average number of buy orders that occurs per unit time at a given price equals the supply of potential buyers times the probability that a generic potential buyer will submit a buy order per unit time, given the price. Makes sense?
Now, we can separate Sell_Orders(Price) in the same way, into a supply term and a probability term. Let Supply_Homes be the supply term–per our assumptions, 1 billion. Let Probability_Sell(Price) be the probability term, with both terms defined analogously to the above. Combining the supply and probability terms, we get,
(3) Sell_Orders(Price) = Supply_Homes * Probability_Sell(Price)
(3) is saying the same thing as (2), except for sellers rather than buyers. Combining (1), (2), and (3), we get a simple and elegant equation for price:
(4) Supply_Buyers * Probability_Buy(Price) = Supply_Sellers * Probability_Sell(Price)
The left side of the equation is the flow of attempted buying. The right side of the equation is the flow of attempted selling. The price that brings the two sides of the equation into balance is the equilibrium price, the price that the market will continually move towards. The market may not hit the price exactly, or be able to remain perfectly stable on it, but if the buyers are appropriately price sensitive, it will get very close, hovering and oscillating in a tight range.
The Buy-Sell Probability Function
Now, we know how many potential buyers–how many apartment dwellers–the market has: 9 billion. We also know how many potential sellers–how many homes and homeowners–the market has: 1 billion. 9 billion is nine times 1 billion. It would seem, then, that the market will face a permanent imbalance–too many buyers, too few sellers. But we’ve forgotten about the price. As the price of a home rises, the portion of the 9 billion potential buyers that will be willing to pay to switch to a home will fall. These individuals do not have infinite pocket books, nor do they have infinite supplies of credit from which to borrow. Importantly, paying a high price for a home means that they will have to cut back on other expenditures–the degree to which they will have to cut back will rise as the price rises, making them less likely to want to buy at higher prices.
Similarly, as the price rises, the portion of the 1 billion homeowners that will be eager to sell and downsize into apartments will rise. In selling their homes, they will be able to use the money to purchase other wanted things–the higher the price at which they sell, the more they will be able to purchase.
This dynamic is what the buy-sell probability functions, Probability_Buy(Price) and Probability_Sell(Price), are trying to model. Crucially, they change with the price, increasing or decreasing to reflect the increasingly or decreasingly attractive proposition that buying and selling becomes as the price changes. By changing with price, the terms make it possible for the two sides of the equation, the flow of attempted buying and selling, to come into balance.
Now, what do these functions look like, mathematically? The answer will depend on a myriad of factors, to include the lifestyle preferences, financial circumstances, learned norms, past experiences, and behavioral propensities of the buyers and sellers. There is some price range in which they will consider buying a home to be worthwhile and economically justifiable–this range will depend not only on their lifestyle preferences and financial circumstances, but also, crucially, on (1) the prices they are anchored to, i.e., that they are used to seeing, i.e., that they’ve been trained to think of as normal, reasonable, versus unfair or abusive, and (2) on what their prevailing levels of confidence, courage, risk appetite, impulsiveness, and so on happen to be. Buying a home is a big deal.
For buyers, let’s suppose that this price range begins at $0 and ends at $500,000. At $0, the average probability that a generic potential buyer–any individual living in an apartment–will submit a buy order in a given one year time frame is 100%, meaning that every individual in an apartment will submit one buy order, on average, per year, if that price is being offered (to change the number from per year to per second, just divide by the number of seconds in a year). As the price rises from $0 to $500,000, the average probability falls to 0%, meaning that no one in the population will submit a buy order at $500,000, ever.
In “y = mx + b” form, we have,
(5) Probability_Buy(Price) = 100% – Price * (100%/$500,000)
The function is graphed below in green:
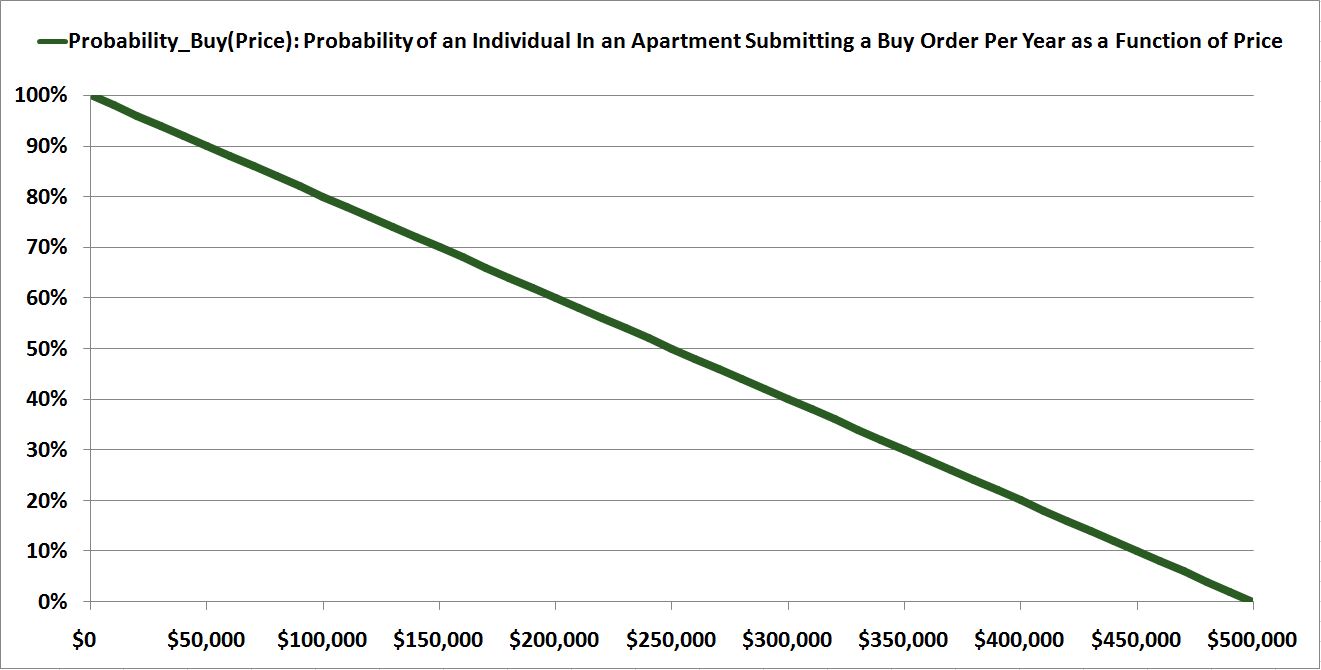
Notice that the function is negatively-sloping. It moves downward from left to right.
For sellers, let’s suppose that the price range begins at $1,000,000 and ends at $400,000. At $1,000,000, the average probability that a generic potential seller–any individual living in a home–will submit a sell order in a given one year time frame is 100%. As the price falls to $400,000, the average probability falls to 0%.
In “y = mx + b” form,
(6) Probability_Sell(Price) = Price * (100%/$600,000) – 66.6667%
The function is shown below in red:
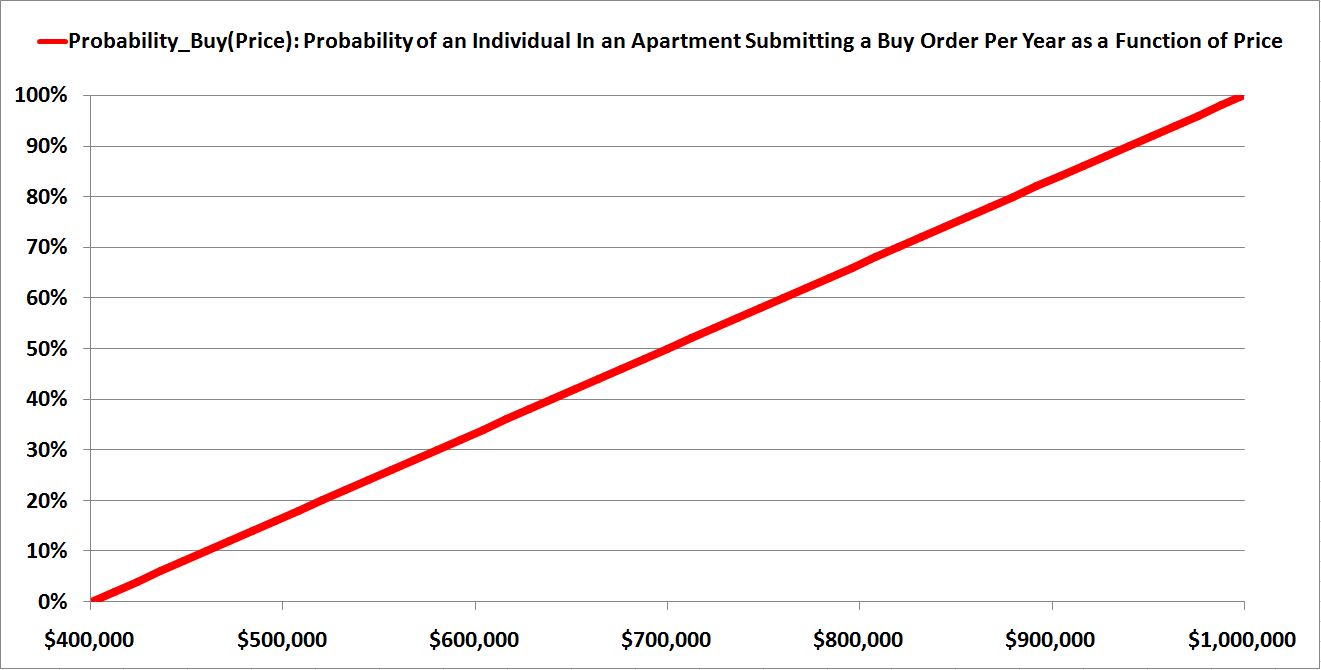
Notice that the function is positively-sloping. It moves upward from left to right.
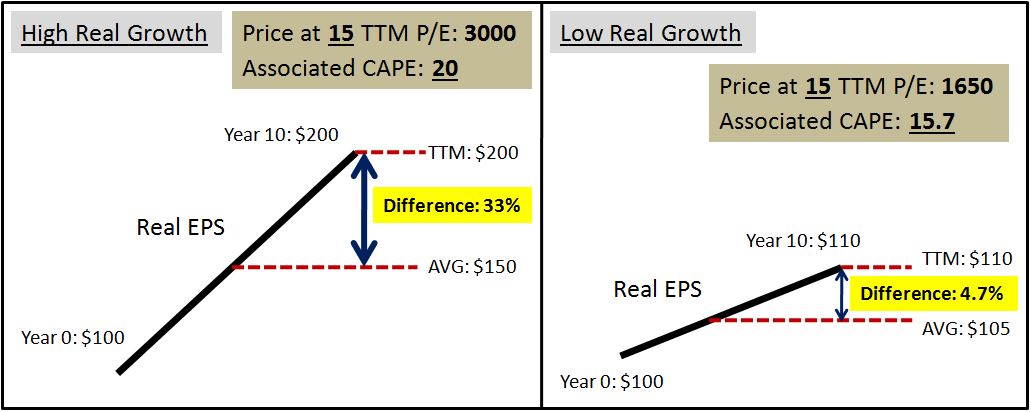
Knowing these buy-sell probability functions, and knowing the number of individuals in apartments and the number of individuals in homes (the supplies that the probabilities will be acting on, 9 billion and 1 billion, respectively), we can plug equation (5) and equation (6) into equation (4) to calculate the equilibrium price. In this case, the price calculates out to roughly $491,525 for a home. The average probability of buying per individual per unit time will be low enough, and the average probability of selling per individual per unit time high enough, to render the average flow of attempted buying equal to the average flow of attempted selling, as required, even as the supply of potential buyers remains 9 times the supply of potential sellers.
Notably, the turnover, the volume of buying and selling, is going to be very low, because the buy-sell probability functions overlap at very low probabilities. The buyers and the sellers are having to be stretched right up to the edge of their price limits in order to transact, with the buyers having to pay what they consider to be a very high price to transact, and the sellers having to accept what they consider to be a very low price to transact.
Now, keeping these buy-sell functions the same, let’s massively shrink the supply of potential buyers, to see what happens to the equilibrium price. Suppose that instead of having 9 billion individuals in the economy living in apartments, suppose that we only have 1 million individuals living in apartments–1 million potential buyers of homes, none of whom are willing to pay more than $500,000. As before, we’ll assume that there are 1 billion homes that can potentially be sold. What will happen to the price? The answer: it will fall from roughly $491,525 to roughly $400,119.
Notice that the price won’t fall by very much–it will fall by only roughly $90,000–even though we’re dramatically shrinking the supply of potential buyers, by a factor of 9,000. The reason that the price isn’t going to fall by very much is that the sellers are sticky–they don’t budge. Per their buy-sell probability functions, they simply aren’t willing to sell properties at prices below $400,000, and so if there aren’t very many people to bid at prices above $400,000, because the supply of buyers has been dramatically shrunk, then the volume will simply fall off. In the former case, with the supply of potential buyers at 9 billion, 155 million homes get sold, on average, in a one year period. In the latter case, with the supply of potential buyers at only 1 million, 200,000 homes get sold, on average, in a one year period.
Behavioral Factors: Anchoring and Disposition Effect
Recall that for buyers, the buy-sell probability function slopes negatively–i.e., falls downward–with price. For sellers, the function slopes positively–i.e., rises upward–with price. The reason the function slopes negatively for buyers is that price is a cost, a sacrifice, to them. The lower or higher the price, the higher or lower that cost, that sacrifice. Additionally, there is a limit to the cost the buyer can pay–he only has so much money, so much access to credit. The reason the function slopes positively for sellers is that price is a benefit, a gain, to them. The lower or higher the price, the lower or higher that benefit, that gain. Additionally, there is a limit to the price that the seller can accept without pain, particularly if he has debts to pay against the assets that he is trying to sell.
In addition to these fundamental considerations, there are also behavioral forces that make the functions negatively-sloping and positively-sloping for buyers and sellers respectively. Of these forces, the two most important are anchoring and disposition effect.
Over time, buyers and sellers become anchored to the price ranges that they are used to seeing. As the price move out of these ranges, they become more averse, more likely to interpret the price as an unusually good deal that should be immediately taken advantage of or as an unfair rip-off that should be refused and avoided.
Anchoring is often seen as something bad, a “mental error” of sorts, but it is actually a crucially important feature of human psychology. Without it, price stability in markets would be virtually impossible. Imagine if every individual entering a market had to use “theory” to determine what an “appropriate” price for a good or service was. Every individual would then end up with a totally different conception of “appropriateness”, a conception that would shift wildly with each new tenuous calculation. Prices would end up all over the place. Worse yet, individuals would not be able to quickly and efficiently transact. Enormous time resources would have to be spent in each individual transaction, enough time to do all the necessary calculations. This time would be spent for nothing, completely wasted, as the calculation results would not be stable or repeatable. From an evolutionary perspective, the organism would be placed at a significant disadvantage.
In practice, individuals need a quick, efficient, consistent heuristic to determine what is an “appropriate” price and what is not. Anchoring provides that heuristic. Individuals naturally consider the price ranges that they are accustomed to seeing and transacting at as “appropriate,” and they instinctively measure attractiveness and unattractiveness against those ranges. When prices depart from the ranges, they feel the change and alter their behaviors accordingly–either to exploit bargains or to avoid rip-offs.
Disposition effect is also important to price stability. Individuals tend to resist selling for prices that are less than the prices for which they bought, and tend to be averse to paying higher prices than the prices could have paid in the recent past. This tendency causes price to be sticky, discinlined to move away from where they have been, as we should want them to be if we want markets to hold together, and not become chaotic.
Housing markets represent an instance where these two phenomena–anchoring and disposition effect–are particularly powerful, especially for sellers. The phenomena is part of what makes housing such a stable asset class relative to other asset classes.
Homeowners absolutely do not like to sell their homes for prices that are lower than the prices that they paid, or that are lower than the prices that they are accustomed to thinking their homes are worth. If a situation emerges in which buyers are unwilling to buy at the prices that homeowners paid, or the prices that homeowners are anchored to, the homeowners will try to find a way to avoid selling. They will choose to stay in the home, even if they would prefer to move elsewhere. If they need to move–for example, to take a new job–they will simply rent the home out; anything to avoid selling the home, taking a loss, and giving an unfair bargain to someone else. Consequently, market conditions in which housing supply greatly exceeds housing demand tend to clear not through a fall in price, but through a drying up of volume, as we saw in the example above.
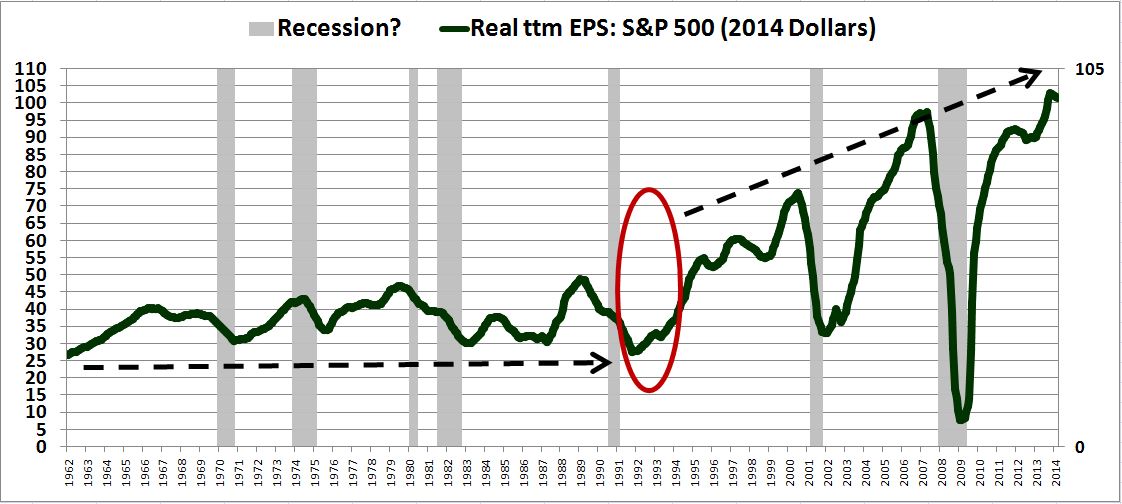
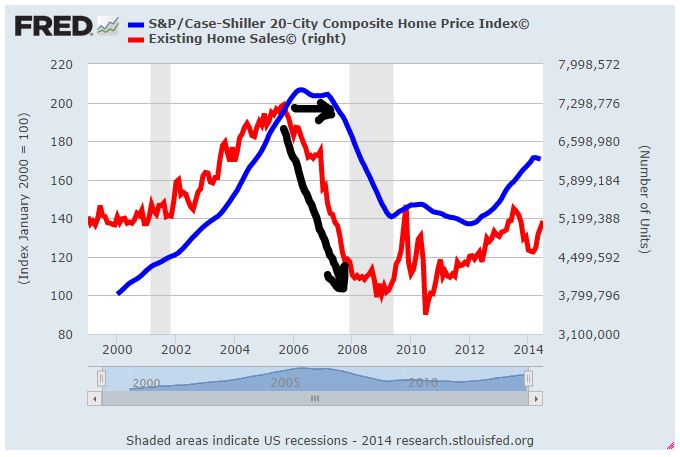
This effect was on fully display in the last recession. Existing home sales topped out in 2005, but prices didn’t actually start falling in earnest until the recession hit in late 2007 and early 2008. Prior to the recession, the homes were held tightly in the hands of homeowners. As long as they could afford to stay in their homes, they weren’t going to sell at a loss. But when the recession hit, they started losing their jobs, and therefore their ability to make their mortgage payments. The result was a spike in foreclosures that put the homes into the hands of banks, mechanistic sellers that were not anchored to a price range and that were not averse to selling at prices that would have represented losses for the prior owners. The homes were thus dumped onto the market at bargain values to whoever was willing to buy them.
When Is Supply Important to Price?
Returning to the previous example, what would be the market outcome if buyers and sellers were completely insensitive to price, such that their buy-sell probability functions did not slope with price? Put differently, what would be the market outcome if the average probability that a potential buyer or seller would buy or sell in a given unit of time–a given year–stayed constant under all scenarios–always equal to, say, 10%, regardless of the price?
The answer is that supply imbalances would cause enormous fluctuations in price. Theoretically, any excess in the number of potential buyers over the number of potential sellers would permanently push the price upward, all the way to infinity, and any excess in the number of potential sellers relative to the number of potential buyers would permanently pull the price downward, all the way to zero.
In concrete terms, if there are 1,001 eager buyers that submit buy orders per unit time, and 1,000 eager sellers that submit sell orders, and if the buyers are completely indifferent to price, then there will always be one buyer left out of the mix. Because that buyer is indifferent to price, he will not hesitate to raise his bid, so as to ensure that he isn’t left out of a transaction. But whoever he displaces in the bidding will also be indifferent to price, and therefore will not hesitate to do the same, raise the bid again–and so on. Participants will continue to raise their bids ad infinitum, continually fighting to avoid being the unlucky person that gets left out.
The only way for the process to end is for 1 of the buyers in the group to conclude, “OK, enough, the price is just too high, I’m not interested.” That is price sensitivity. Without it, a stable equilibrium amid a disparate supply of potential buyers and sellers cannot be achieved.
We now have the ability to answer an important question at the heart of this piece: when is “supply” most important to price, most impactful? The answer is, when price sensitivity is low. If the probability of buying doesn’t fall quickly in response to an increase in price, and if the probability of selling doesn’t fall quickly in response to a decrease in price, then even a small change in the supply of potential buyers or sellers will be able to create a large change in the price outcome. In contrast, if the price sensitivity is high, if the probability of buying falls quickly in response to price increases, and the probability of selling falls quickly in response to price reductions, then the price will be able to remain steady, even in the presence of large supply excursions. Intuitively, the reason the price will be able to remain steady is that the potential buyers and sellers will be holding their grounds–they won’t be budging off of their desired price ranges simply to make transactions happen.
Low price sensitivity is part of the reason why small speculative stocks with ambiguous but potentially exciting futures–low-float stocks with large potentials that are difficult to confidently value and that exhibit significant price reflexivity–tend to be highly volatile. If there is a net excess or shortage of eager buyers in these stocks relative to eager sellers, the price will end up changing. But the change will not correct the excess or shortage. Therefore the change will not stop. It will keep going, and going, and going, and going.
To use a relevant recent example, if there is a shortage in the supply of $LOCO shares being offered in an IPO relative to the amount of $LOCO that investors want to allocate into, then the price is going to increase. For the market in $LOCO to remain stable, this price increase will need to depress the demand, reduce the amount of $LOCO that investors want to allocate into. If the price increase fails to depress the demand, or worse, if it does the opposite, if it increasess the demand–for example, by drawing additional attention to the name and increasing investor optimism about the company, given the rising price–then the price is going to get pushed higher and higher and higher.
At some point, something will have to reverse the process, as the price can’t go to infinity. In the case of $LOCO, more and more people might start to ask themselves, have things gone to far? Is this stock a bubble that is about to burst? An excess of sellers over buyers will then emerge, and the same process will unfold in the other direction. When the price falls, the fall will not sufficiently clear the excess demand to sell, and may even increase it, by fueling anxiety, skepticism and fear on the part of the remaining holders. And so the price will keep falling, and falling, and falling.
Now, if we shift from $LOCO IPO to a market where price sensitivity is strong, this dynamic doesn’t take hold. To illustrate, suppose that the treasury were to issue a massive, gargantuan quantity of three month t-bills. The same instability would not emerge. The reason is that there is a strong inverse relationship between the price of three month t-bills and the demand to own them, a relationship held in place by the possibility of direct arbitrage in the banking system. Recall that a three month t-bill offers a return that is fully-determined and free of credit risk. It also carries no interest rate risk beyond a period of three months (the money will have been returned by then). Thus, as long as the Fed holds overnight interest rates steady over the next three months, as the current Fed has effectively promised to do, banks will be able to borrow funds and purchase three month t-bills, capturing any excess return above the overnight rate that the bills happens to be offering, without taking on any risk. And so any fall in the price of a three month treasury bill, and any rise in the yield, will represent free money to banks. That free money will attract massive buying interest, more than enough to quench whatever increased selling flow might arise out of a large increase in the outstanding supply. Ultimately, when it comes to short-term treasuries, supply doesn’t matter much to price.
Extending the Model to Financial Assets: Equity and Credit
To extend the housing model to financial assets, we begin by noting that units of financial “wealth”–that is, units of the market value of portfolios, in this case measured in dollars–are analogous to “individuals” in the housing model. Just as individuals could either live in homes or apartments–and had to choose one or the other–units of financial “wealth” can either be held in the form of equity (stocks), credit (bonds), or money (cash). Just as every home had to have an owner and every apartment a tenant living inside it, every outstanding unit of equity, credit, and money in existence has to have a holder, has to be a part of someone’s portfolio, with a portion of the wealth contained in that portfolio stored inside it.
Now, to make the model fully analogous, we need to reduce the degrees of freedom from three (stocks, bonds, cash) to two (stocks, cash). So we’re going to treat bonds and cash as the same thing, referring to both simply as “cash.” Then, investors will have to choose to hold financial “wealth” either in the form of “stocks”, or in the form of “cash”, just as “individuals” had to choose to live either in “homes”, or in “apartments.”
Let’s assume, then, that our stock market consists of some amount of cash–some number of individual dollars–and some amount of stock, some number of shares with a total dollar value determined by the price. Let’s also assume that the same computer is there to take buy and sell orders–orders to exchange cash for stock or stock for cash respectively. The computer processes orders and moves the price towards equilibrium in the same way as before, by displaying a price–an exchange rate between stock and cash–then taking orders, then raising or lowering the price in the next moment based on where the excess lies.
The derivation of the price equation ends up being the same as in the housing model, and gives the following result.
(7) Supply_Cash * Probability_Buy(Price) = Supply_Stock(Price) * Probability_Sell(Price)
Here, Supply_Cash is the total dollar amount of cash in the system. Probability_Buy(Price) is the average probability, per dollar unit of cash in the system, per unit of time, that the unit of cash will be sent into the market to be exchanged for stock at the given price. Supply_Stock is the the total market value of stock in existence. Probability_Sell(Price) is the average probability, per dollar unit of value of stock in the system, that the unit will be sent into the market to be exchanged for cash at the given price.
Now, where this model differs from the previous model is that Supply_Stock, the total market value of stock in existence, which is the total amount of stock available for investors to allocate their wealth into, is a function of Price. It equals the number of number of shares times the price per share.
(8) Supply_Stock(Price) = Number_Shares * Price
Unlike in the housing model, the supply of stock in the stock market expands or contracts as the price rises and falls. This ability to expand and contract helps to quell excesses that emerge in the amount of buying and selling that is attempted. If investors, in aggregate, want to allocate a larger portion of their wealth into stocks than is available in the current supply, the price of stocks will obviously rise. But the rising price will cause the supply of stocks–the shares times the price–to also rise, helping, at least in a small way, to relieve the pressure. The same is true in the other direction.
Combing (7) and (8), we end up with a final form for the equation,
(9) Supply_Cash * Probability_Buy(Price) = Number_Shares * Price * Probability_Sell(Price)
Note that we’re using this equation to model stock prices, but we could just as easily use the equation to model the price of any asset, provided that simplifying assumptions are made.
A more accurate form of the equation would include a set of terms to model the possibility of margin buying and short selling. These terms are shown in green,
(10) Supply_Cash * Probability_Buy(Price) + Supply_Borrowable_Cash * Probability_Borrow_To_Buy(Price) = Number_Shares * Price * Probability_Sell(Price) + Number_Borrowable_Shares * Price * Probability_Borrow_To_Sell(Price)
But the introduction of these terms makes the equation unnecessarily complicated. The extra terms are not needed to illustrate the underlying concepts, which is all that we’re trying to do.
A Growing Cash Supply Chases A Narrowing Stock Supply: What Happens?
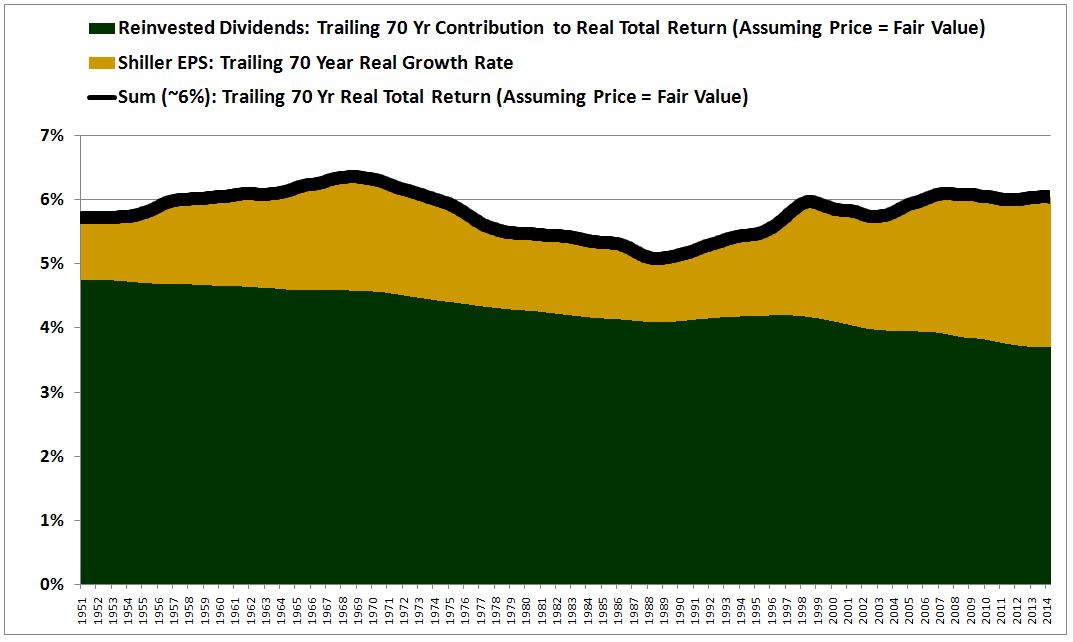
It is commonly believed that the stock market–the aggregate universe of common stocks–rises over time because earnings rise over time. Investors are sensitive to value. They estimate the future earnings of stocks, and decide on a fair multiple to pay for those earnings. When the stock market is priced below that multiple, they buy. When the stock market is priced above that multiple, they sell. In this way, they keep the price of the stock market in a range–a range that rises with earnings over time.
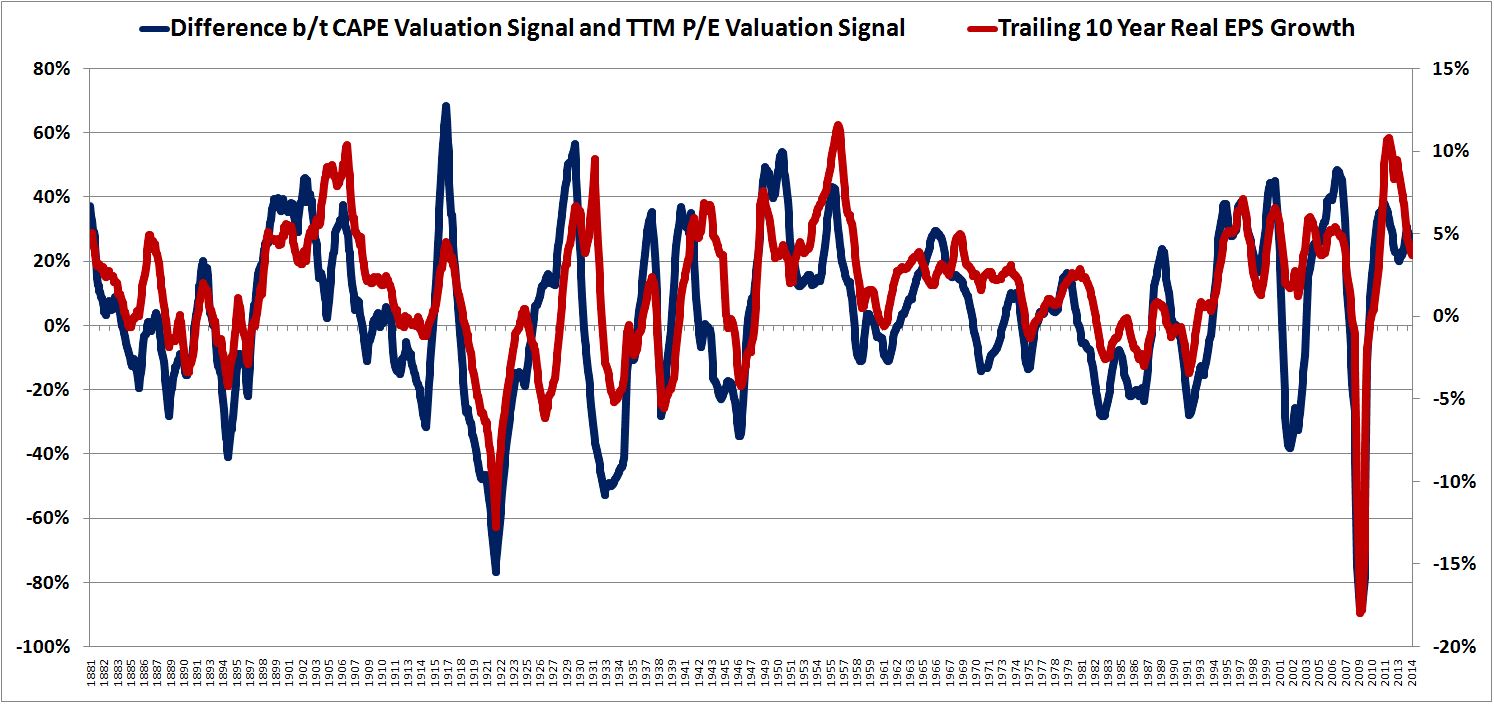
In a set of pieces from last year (#1, #2), I proposed a competing explanation. On this explanation, the stock market rises over time because we operate in an inflationary financial system, a system in which the quantity of money and credit are always growing. Given its aversion to dilution, the corporate sector does not issue enough new shares to keep up with this growth. Consequently, a rising quantity of money and credit is left to chase after a limited quantity of shares, pushing the prices of shares up through a supply effect. Conveniently, as prices rise, the supply of stock rises, bringing the supply back into par with the supply of money and credit.
The truth, of course, is that both of these factors play a role in driving the stock market higher. Which factor dominates depends on the degree of price sensitivity–or, in this case, the degree of value sensitivity–of the buyers and sellers. In a world where buyers and sellers are highly sensitive to the price-earnings ratio, the supply effect will not exert a signficant effect on prices. Prices will track with earnings and earnings alone. In a world where buyers and sellers are not highly sensitive to the price-earnings ratio, or to other price-based measurements of value, the supply effect will become more significant and more powerful.
We can illustrate this phenomenon by running the model computationally, with random offsets and deviations inserted to help simulate what happens in a real market. Assume, that there are 1,000,000 shares of stock in the market, and $2B dollars of cash. Assume, further, that each share of stock earns $100 per year in profit. Finally, assume that the buy-sell probability functions for buyers and sellers are symmetric cumulative distribution functions (CDF) of Gaussian distributions with very small standard deviations. These functions take not only price as input, but also earnings. They compute the PE ratio at a given price and output a probability of buying or selling based on it.
The functions look like this:
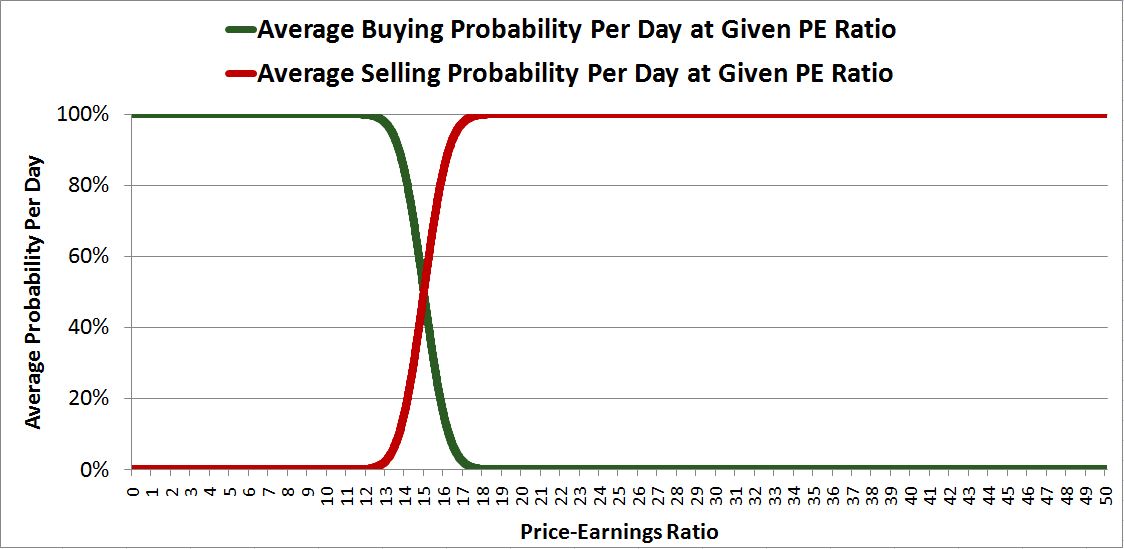
We’ve centered the functions around a PE ratio of 15, which we’ll assume is the “normal” PE, the PE that market participants are trained and accustomed to view as “fair.” Per the above construction of the function, at a PE 15, there is a 50% chance per day that a given dollar in the system will be submitted to the market by a buyer to purchase stock, and a 50% chance per day that a given dollar’s worth of stock in the system will be submitted to the market by a seller to purchase cash (what selling is, inversely). As the PE rises above 15, the buying probability falls sharply, and the selling probability rises sharpy. As the PE falls below 15, the buying probability rises sharply, and the selling probability falls sharply. Evidently, the buyers and sellers are extremely price and valuation sensitive. 15 plus or minus a point or two is the range of PE they are willing to tolerate; whenever that range is breached in the unattractive direction, they quickly step away.
Now, if we wanted to make the function more accurate and realistic, we would make it a function not only of price and earnings, but also of interest rates, demographics, growth outlook, culture, past experience, and so on–all of the “variables” that conceivably influence the valuations at which valuation-sensitive buyers and sellers are likely to buy and sell. We’re ignoring these factors to keep the problem simple.
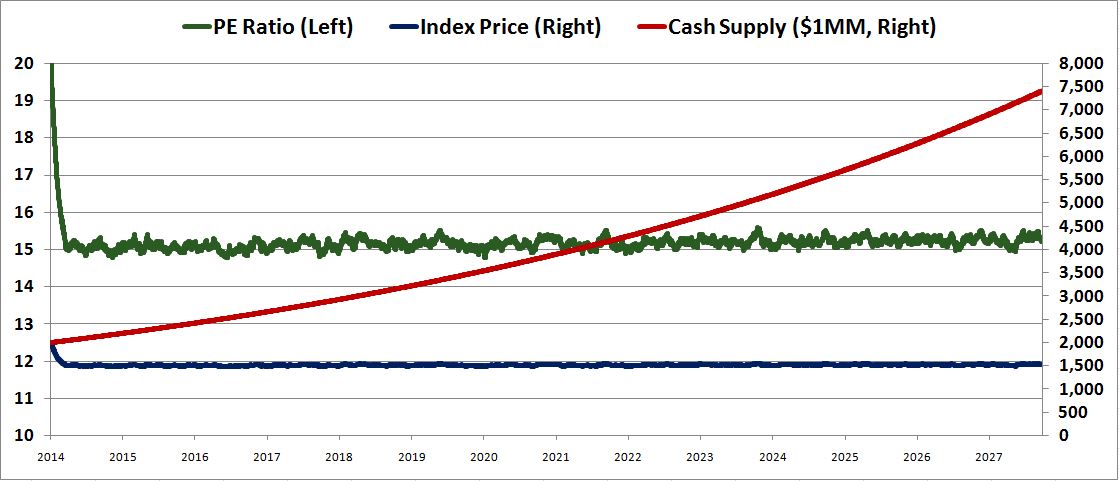
In the first instance, let’s assume that the supply of cash stays constant and the earnings stay constant. Starting with a price of 2,000 for the index, holding the number of shares constant, and iterating through to an equilibrium, we get a chart that shows the trajectory of price over time, from now, the year 2014, to the year 2028.
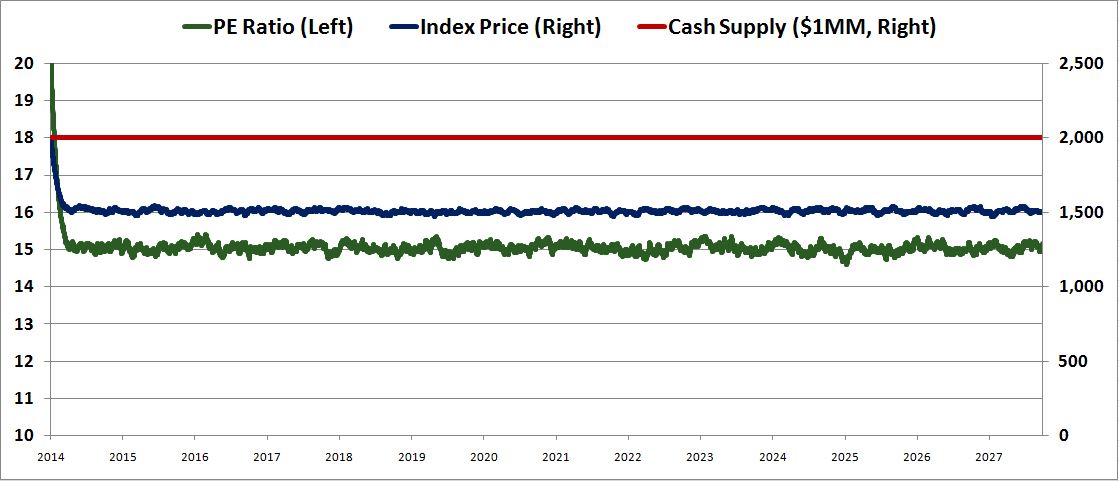
The result is as expected. If the buyers are highly value sensitive, and if the earnings aren’t growing, then the price should settle tightly on the price range that corresponds to a “normal” PE ratio–in this case, a range around 1500, 15 times earnings, which is what we see.
Now, let’s run the simulation on the assumption that the supply of cash stays constant and the earnings grow at 10% per year.
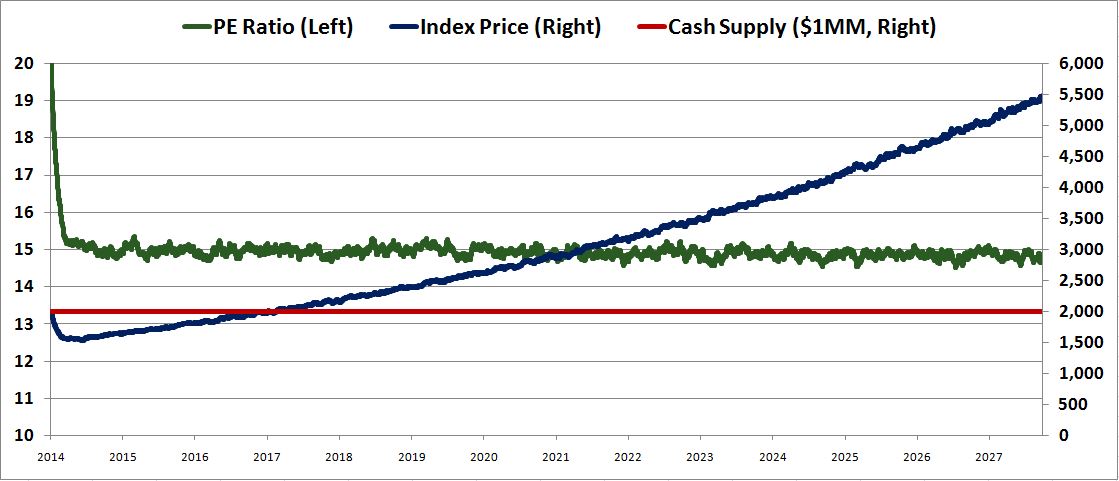
The result is again as expected. The index price, the blue line, initially falls from 2000 to 1500 to get from a PE ratio of 20 to the normal PE ratio of 15. It then proceeds to grow by 10% per year, commensurately with the earnings. The cash supply stays constant, but this doesn’t appreciably hold back the price growth, because the buyers are value sensitive. They are going to push the price up to ensure that the PE ratio stays around 15, no matter the supply.
If you look closely, you will notice that the green line, the PE ratio, drifts slightly below 15 as time passes. This drift is driven by the stunted supply effect. The quantity of cash is not growing, which holds back the price growth by a miniscule amount relative to what it would be on the assumption of a perfectly constant 15 PE ratio. The supply effect in the scenario is tiny, but it’s not exactly zero.
Now, let’s run the simulation on the assumption that the supply of cash rises at 10%, but the earnings stay constant.
The result is again as expected. The index price stays constant, on par with the earnings, which are not growing. The cash supply explodes, but this doesn’t exert an appreciable effect on the price, because the buyers are extremely value sensitive.
If you again look closely, you will notice that the green line, the PE ratio, drifts slightly above 15 as time passes. This drift is again driven by the stunted supply effect. The quantity of cash is growing rapidly, and this pushes up the price growth by a miniscule amount relative to what it would be on the assumption of a perfectly constant 15 PE ratio.
Now, let’s introduce a buy-sell probability function that is minimally sensitive to valuation, and see how the system responds to supply changes. Instead of using CDFs of Gaussian distributions with very small standard deviations, we will now use CDFs of Gaussian distributions with very large standard deviations. In the actual simulations, we will also insert larger random deviations and offsets to help further model the price insensitivity.
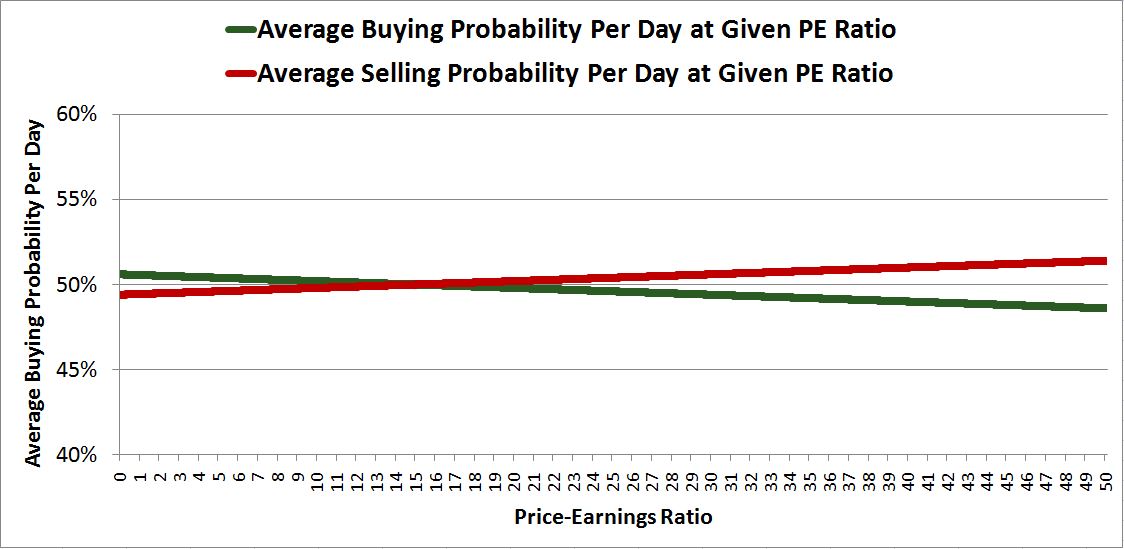
Evidently, under these new functions, the buying and selling probabilities remain essentially stuck around 50%, regardless of the PE ratio. The functions are only minimally negatively-sloping and positively-sloping. What this means qualitatively is that buyers and sellers don’t care much about the PE ratio, or any other factor related to price. Price is not a critical consideration in their investment decision-making process. They will accept whatever price they can get in order to take on or avoid the desired or unwanted exposure.
Now, let’s run the simulation on the assumption that the cash supply grows at 10%, while the earnings stay constant.
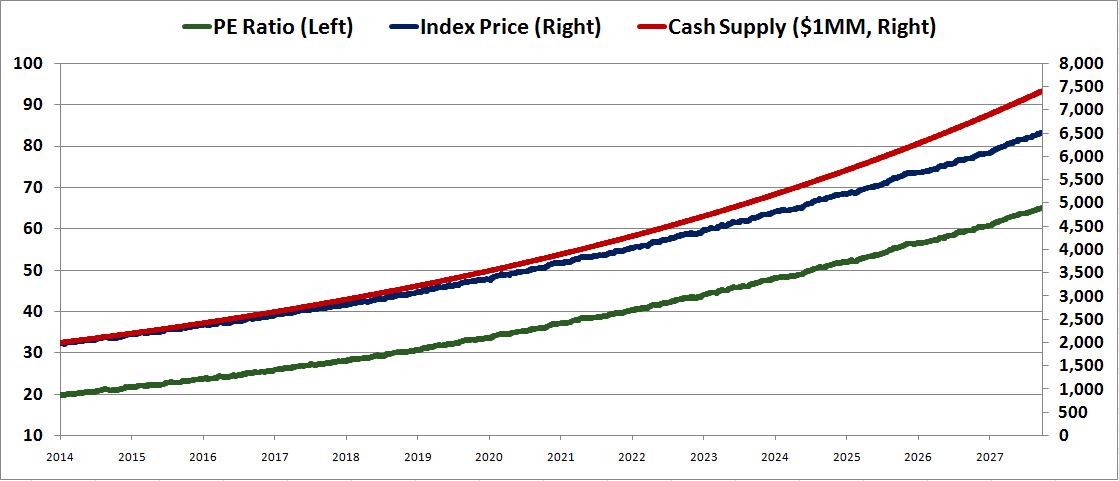
Here, the outcome changes significantly. The index price, shown in blue, separates from the earnings, and instead tracks with the growing cash supply, shown in red. Instead of holding at 15, the PE ratio, shown in green, steadily expands, from 20 in 2014 to roughly 65 in 2028. All of the market’s “growth” ends up being the result of multiple expansion driven by the growth in the cash supply–growth in the amount of cash “chasing” the limited amount of shares. Now, there is still some valuation sensitivity, which is why the index price fails to fully keep up with the rising cash supply. The valuation sensitivity acts as a slight headwind.
Now, let’s run the simulation on the assumption that the earnings grow at 10%, but the cash supply shrinks by 10%.
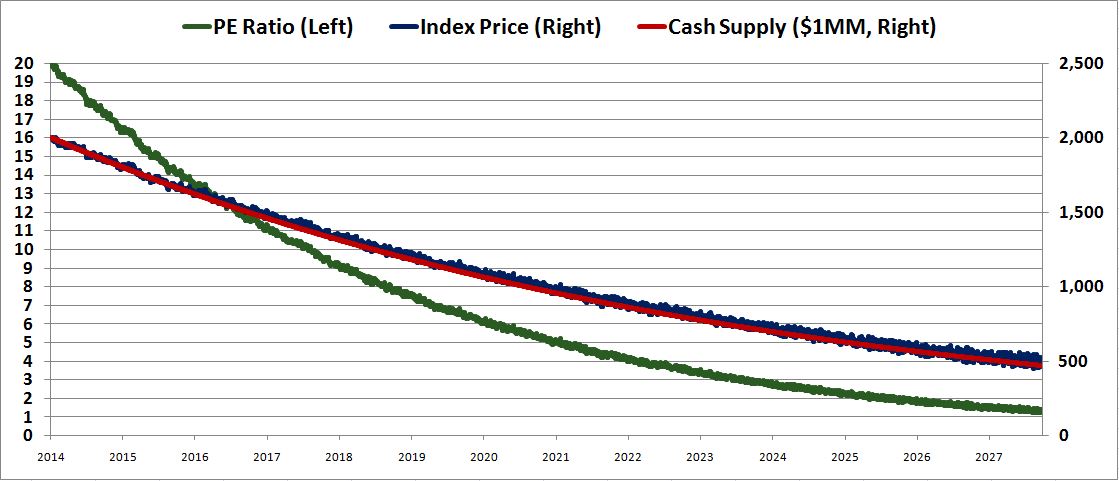
Once again, the price tracks with the contracting supply of cash, not with the growing earnings. Consequently, the PE ratio falls dramatically–from 20 down to 1.25.
Supply Manipulations in a Live Experiment
Everything that we’ve presented so far is theoretical. We don’t have a buy-sell probability function for real buyers and sellers that we could use to determine the prices that their behaviors will produce in a market with a growing supply of cash and fluctuating earnings. Even if we could come up with such a function, it would not be useful for making actual price predictions, as it would contain far too many fuzzy and hard-to-measure variables, and would always be changing in unpredictable ways.
At the same time, the modeling that we’re doing here is useful in that it allows us to think more clearly about the way that supply factors interact with buying and selling probability factors to determine price. When confronted with questions about the impact of supply factors in specific market circumstances, the best approach to evaluating these questions is to explore the kinds of buying and selling probabilities that those circumstances will lend themselves to–that is, the kind of buy-sell probability functions the circumstances will tend to produce.
If the circumstances will tend to produce significant price and value sensitivity–that is, sharply negatively-sloping buying probabilities and sharply positively-sloping selling probabilities, as a function of price–then supply will not turn out to be a very important or powerful factor in determining price. As supply differences lead to price changes, the number of people that want to buy and sell at the given price will quickly adjust, arresting the price changes and stabilizing the price.
But if the circumstances will tend to lend themselves to price and valuation insensitivity–that is, flatly-sloping buying and selling probabilities, or worse, reflexive buying and selling probabilities, buying probabilities that rise with rising prices, and selling probabilities that rise with falling prices–then supply as a factor will prove to be very important and very powerful. As supply differences emerge and cause price changes, the number of people that want to buy and sell at the given price will not adjust as needed, causing the price to continue to move, the momentum to continue to carry.
With this in mind, let’s qualitatively examine a famous genre of experiments that economists have performed to test the impact of supply on price. In these experiments, a large closed group of market participants are endowed with a portfolio of cash or stock, and are then left to trade the cash and stock with each other.
The shares of stock pay out a set quantity of dividends on a scheduled periodicity throughout the scenario, or at the end, and then they expire worthless. Each dividend payment equals some constant value, plus a small offset that is randomly computed in each payment period.
At any time, it’s easy to calculate what the intrinsic value of a share is. It’s the sum of the expected future dividend payments up to maturity, which is just the number of dividend payments that are still left to be paid, times the value of each payment. The offset to the payments is random, it acts in both directions, therefore it effectively drops out of the analysis. Granted, the offsets insert an “uncertainty” into the value of the shares, the undesirability of which investors might choose to discount. But the uncertainty is small, and the participants aren’t that sophisticated.
Before the experiment begins, the experimenters teach the participants how to calculate the intrinsic value of a share. The experimenters then open the market, and allow the participants to trade the assets with each other (through a computer). Crucially, whatever amount of money the participants end up with at the end of the experiment, they get to keep. So there is a financial incentive to trade and invest intelligently, not be stupid.
The experiment has been run over and over again by independent experimenters, incorporating a number of different individual “tweaks.” It’s been run on large groups, small groups, financially-trained individuals, non-financially-trained individuals, over short time periods, long time periods, with margin-buying, without margin-buying, with short-selling, without short-selling, and so on.
The experiments consistently produce results that defy fundamentals, results in which prices deviate sharply from fair value, when in theory they shouldn’t. Shown below is a particularly egregious example of the deviation, taken from an experiment run on 304 economic students at Indiana University consisting of a 15 round trading period that lasted 8 weeks:
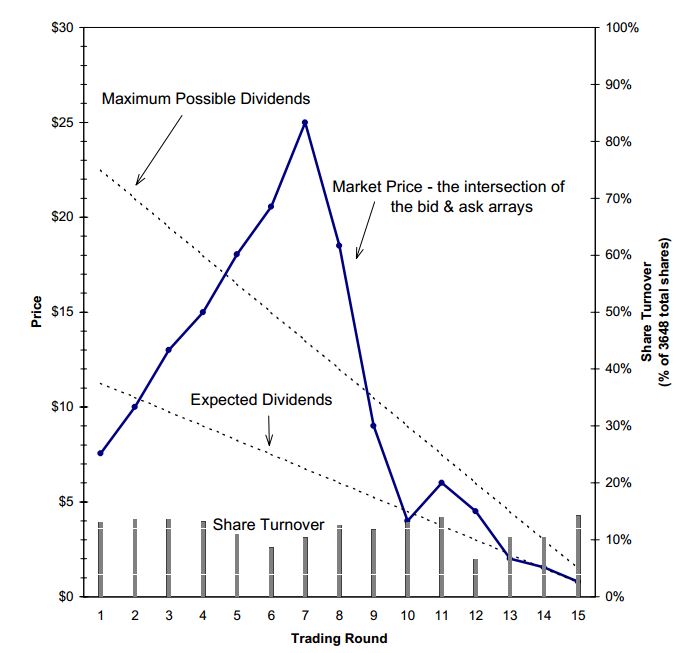
As you can see, the price deviates sharply from intrinsic value. In the early phases, the buyers lack courage to step up and buy, so the price opens below fair value. As the price rises, the buyers gain confidence, and more and more try to jump on board. This process doesn’t stop when the limits of fair value are reached; it keeps going. Buyers throw caution to the wind, and push the market into a bubble. The bubble then bursts. As the maturity nears, the price gravitates back towards intrinsic value.
If we think about the experiment, it’s understandable that this outcome would occur, at least in certain circumstances. “As long as the music is playing, you have to get up and dance.” Right? Valuation is important only to the extent that it impacts price on the time horizons that investors are focused on. In the beginning of the experiment, the investors are not thinking about what will happen at the end of the experiment, which is many months away. They are thinking about what price they will be able to sell the security for in the near term. They want to make money in the near-term, do what the other successful people in the game seem to be doing. As they watch the price travel upward, above fair value, they start to doubt whether valuation is something that they should be focusing on. They conclude that valuation doesn’t “work”, that it’s a red herring, that focusing on it isn’t the way you’re supposed to play the game. So they set it aside, and focus on trying to profit from the continued momentum instead. In this way, they contribute to the growing excesses, and help create the eventual bubble.
As the security gets closer to its maturity, more and more participants start worrying about valuation. It can’t be ignored forever, after all, for the bill’s eventually going to come due. And so as the experiment draws to a close, the price falls back to fair value.
Now, the question that we want to ask is, if we change the aggregate supply of cash in this experiment relative to the supply of shares, what will happen? Of course, we already know the answer. The valuation excesses will grow, multiply, inflate. The buyers, after all, have demonstrated that they are not value sensitive–if they were, they wouldn’t let the price leave the fair value range. As the price rises in response to the supply imbalances, the buyers aren’t going to pull back, and the sellers aren’t going to come forward–therefore, the imbalances aren’t going get relieved. The price will keep rising until something happens to shift the psychology.
Interestingly, one practical finding from the experiment is that the most effective way to arrest the excess is to reduce the supply of cash relative to the supply of shares. When you reduce the supply of cash, the bubbles have a much more difficult time forming and gaining traction. Sometimes, they don’t form at all. Central Banks of the world, take note!
Now, some have objected to the results of the experiments, arguing that the participants often don’t understand how the maturity process works–that they often don’t recognize, until late in the game, that the security is going to expire worthless. Put differently, the participants wrongly envision the dividends as investment returns on a perpetual security, rather than as returns of capital on a decaying security. For our purposes, this potential flaw in the experiment doesn’t really matter, for even if the value of the security is misunderstood, that alone shouldn’t cause supply changes to appreciably impact prices. Supply should only appreciably impact prices if investors are not paying attention to value. Evidently, they aren’t.
A potentially more robust version of the experiment is one where there are no interim dividends, but only a single final payment, a single return of capital, paid to whoever owns the shares at the end. In this version of the experiment, it’s painfully obvious what the security is worth, there is no room for confusion. The security is worth the expected value of the final payment.
Professor Gunduz Caginalp of the University of Pittsburgh ran the experiment under this configuration, allowing groups of participants to trade cash and shares that pay an expected value of $3.60 at maturity (the actual value has a 25% chance of being $2.60, a 25% chance of being $4.60, and a 50% of being $3.60). In one version, he kept the supply of cash roughly equal to the supply of shares, in another version, he roughly doubled the supply of cash. He then ran each version of the experiment multiple times on different groups of participants to see whether the different versions of the experiment produced different prices. The following chart shows the average price evolution for each version:
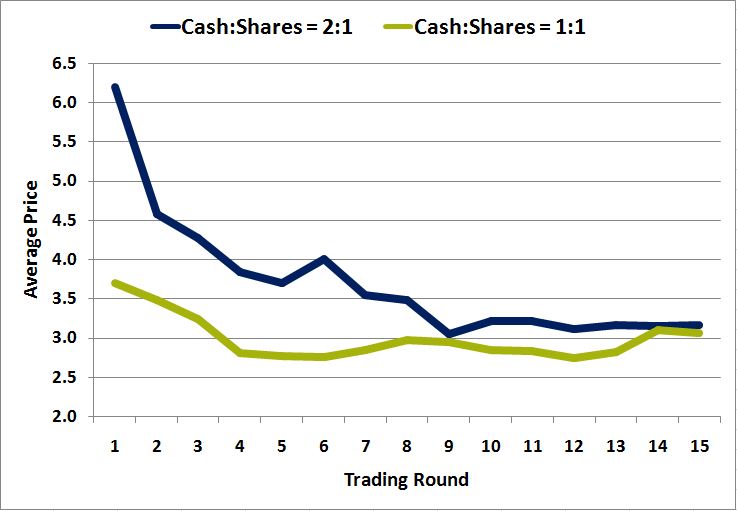
As you can see, the version in which the supply of cash is twice the supply of shares (blue line) produces prices that are persistently higher than the version in which the supply of cash equals the supply of shares. This is especially true in the early trading rounds of the experiment–as the experiment draws to an end, valuation sensitivity increases, and the average prices of the two versions converge.
Interestingly, in the later rounds, the market in the high cash scenario seems to have an easier time moving the price to fair value than in the low cash scenario. In the low cash scenario, a meaningful discount to fair value remains right up until the last few rounds, a discount that defies fundamental justification (why should the price be roughly $2.75 in round 12 when there is a 75% change of the price being substantially higher, and essentially a 0% chance of the price being lower, at maturity?). This peculiarity illustrates the previous point that even when valuation is the dominant consideration for market participants, even when the market in aggregate is trying to move the price to fair value, supply still matters–it can nudge the market in the right or wrong direction.
It turns out that the only consistently reliable way to prevent an outcome in which individuals push prices in the experiment out of the range of fair value is to run the experiment on the same subjects multiple times–then, the investors learn their lessons. They start paying attention to valuation.
Evidently, the perceived connection between valuation and investment returns–the connection that leads investors to care about value, and to use it in their investment processes–is learned through experience, at least partially. To reliably respect valuation, investors often need to go through the experience of not respecting it, buying too high, and then getting burned. They need to lose money. Then, valuation will become important, something to worry about. Either that, or investors need to go through the experience of buying at attractive prices and doing well, making money, being rewarded. In response to the supportive feedback, investors will grow hungry for more value, more rewards.
As with all rules that investors end up following, when it comes to the rule “though shalt respect value”, the reinforcement of punishment and reward, in actual lived or observed experience, cements the rule in the mind, and conditions investors to obey it.